- 产品简介
- 系统数据介绍
- 一、数据范围
- 二、数据更新频率
- 三、品牌/车系识别方式
- 四、核心指标定义
- 五、核心指标定义
- 系统数据介绍
- 一、品牌总览
- 二、品牌剖析
- 三、品牌对标
- 四、品牌形象
- 五、热门话题
- 六、微博人群画像、抖音人群画像、汽车之家人群画像
- (一)信息来源
- (二)筛选器
- (三)性别分布 及 年龄分布
- (四)认证分布(微博人群画像)
- (五)地区分布 及 城市级别分布
- (六)常用客户端(微博人群画像)
- (七)活跃时间(小时)(微博人群画像)
- (八)粉丝数量分布(微博人群画像)
- (九)用户感兴趣内容(微博人群画像、抖音人群画像)
- (十)关注用户排名(微博人群画像、抖音人群画像)
- (十一)关注微博话题 及 关注抖音话题
- (十二)话题原文(微博人群画像)
- (十三)裸车购买价格分布(汽车之家人群画像)
- (十四)购车时间与发表时间间隔分布(汽车之家人群画像)
- (十五)行驶里程分布(单位:公里)(汽车之家人群画像)
- (十六)油耗/电耗分布(单位:百公里)(汽车之家人群画像)
- (十七)TOP10收藏排名(汽车之家人群画像)
产品简介 #
品牌分析通过量化的指标,帮助业务部门直观地查阅各大汽车品牌/车系在社媒上的营销表现;并支持对品牌/车系进行维度剖析,归因营销表现,助力企业优化营销策略,达到降本增效的目的。

系统数据介绍 #
一、数据范围 #
(一)数据源 #

(二)可选时间 #
系统可选择查阅的数据时间范围:2023年1月1日至今。
二、数据更新频率 #
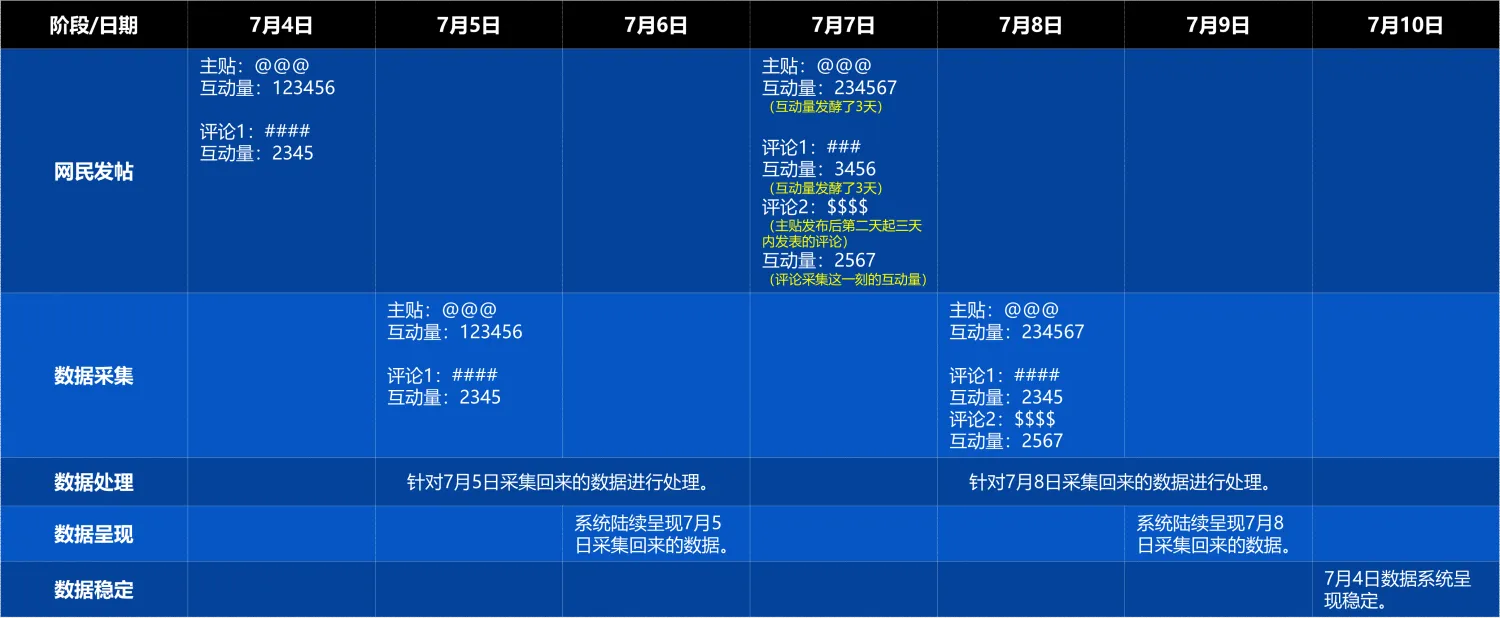
● 系统每天会陆续呈现前一天数据;为了实现数据覆盖的全面性,我们每天会安排多轮主贴采集;同时互动量和评论贴会安排T+3天后采集。
● 主贴:发帖日+2天,系统数据趋于稳定可用作分析。互动量和评论:发帖日+6天,系统数据趋于稳定可用作分析。如下图:
三、品牌/车系识别方式 #
主贴和评论分别依据下图规则进行识别(以“雷克萨斯”为例)

四、核心指标定义 #
(一)声量 #
1.声量定义: #
与分析对象相关的帖子量总和,若在同一条帖子被提及多次,声量记1。 主贴、转发或者评论都分别计为1个声量。
2.不同层级对象(集团、品牌、车型)的声量集合关系如下: #

(二)互动量 #
1.互动量定义: #
针对分析对象被提及文本的所有互动指标之和,包括转发数/评论数/点赞数/收藏数等,如下图:

1.互动量更新机制: #

(三)正面声量及负面声量 #
- 系统中,有两类正面声量,和两类负面声量。一类是针对分析对象得出的正面声量,一类是针对分析对象中某个维度得出的正面声量;负面声量亦如此。
- 针对分析对象得出的正面声量,是通过实体情感算法识别得出的结果。以雷克萨斯ES为例:在一篇帖子中,先定位到雷克萨斯ES的位置,然后再找到雷克萨斯ES附近针对它的情绪表达。
- 针对分析对象,某个维度,得出的正面声量,是通过智能三元组算法识别得出的结果。以雷克萨斯ES-外观为例:在一篇帖子中,先明确这篇帖子讲到的车系是雷克萨斯ES,然后定位到外观的位置,最后再找到针对外观的情绪表达。
(四)NSR #
1.定义: #
NSR(Net Sentiment Rate), 净情感度。通过计算品牌/车系在网上正面与负面评价比例来分析网络情绪倾向。
2.统计逻辑: #
NSR=(正面声量-负面声量)/(正面声量+负面声量)*100%。注意:这里的正面声量与负面声量使用的是实体情感算法得出的样本。
五、核心指标定义 #
(一)声量类型 #
1.不同声量类型的定义: #
1.1 BGC: #
即品牌生产并发布的内容,是品牌为了向用户传递品牌形象、服务理念、产品特色等而生产并发布的内容。BGC通常由品牌自己的内容团队制作,包括品牌故事、公司简介、企业文化等。
1.2 PGC: #
Professionally-generated Content,即专业生产内容,是由具有一定影响力的达人或KOL为了向用户传递自己的专业知识和见解而生产并发布的内容。生产创作内容质量可控性更强,对生产者知识背景和专业资质的要求较高。部分专业内容生产者既是平台的用户,也以专业身份(专家)贡献具有一定水平和质量的内容(如资深用户的点评)。在内容创作方面,体现为更加专业化、优质化、垂直化的内容。PGC通常具有更高的质量和价值,能够吸引更多用户的关注和认可。
1.2.1 PGC-经销商: #
由经销商发表的帖子,如下图:

1.2.2 PGC-二手车: #
由二手车商发表的帖子,如下图:

1.2.3 PGC-汽车服务: #
由汽车服务商发表的帖子,如下图:

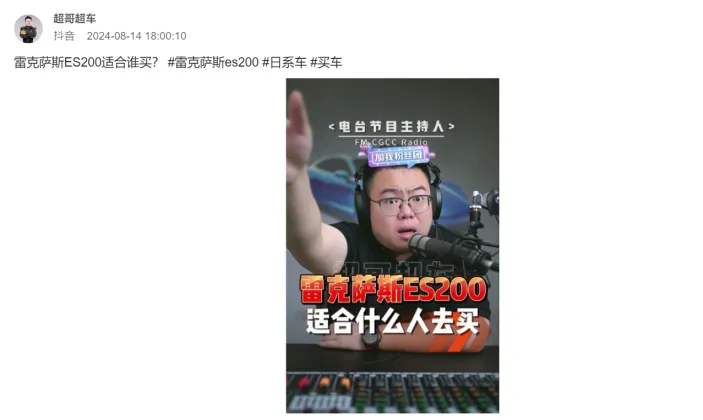
1.2.4 PGC-其他: #
由汽车领域的达人发表的帖子。如下图。这类用户以汽车领域KOL为主。KOL(Key Opinion Leader),是指关键意见领袖,拥有更多的产品信息,对某群体的购买行为有较大影响力的人。
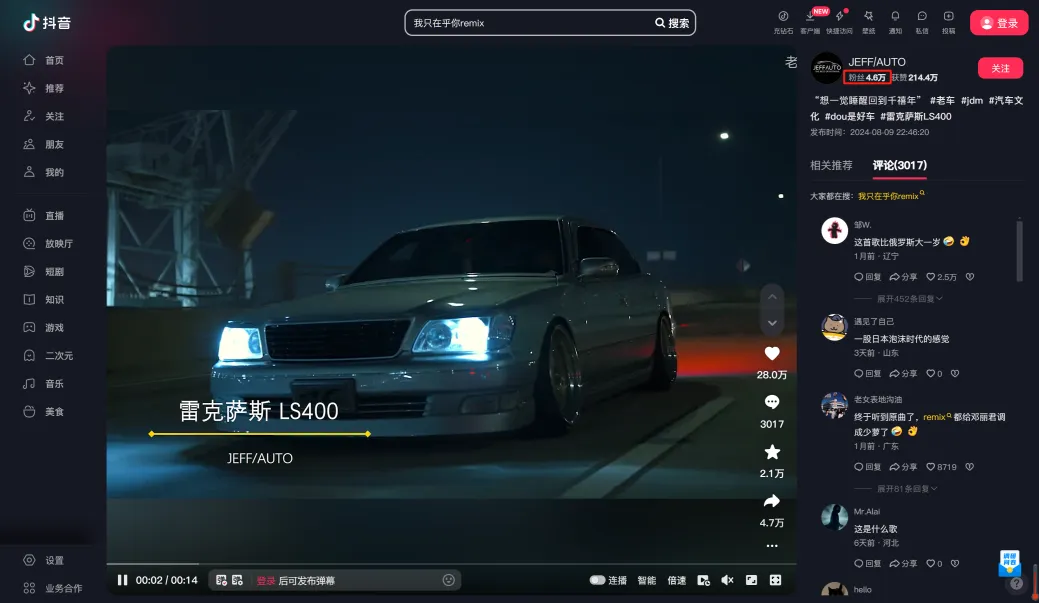
1.3 KOC: #
Key Opinion Consumer,即关键意见消费者,对应KOL(Key Opinion Leader,关键意见领袖)。一般指能影响自己的朋友、粉丝,产生消费行为的消费者。相比于KOL,KOC的粉丝更少,影响力更小,优势是更垂直、更便宜。如下图:
1.4 UGC: #
User-Generated Content,即素人用户生产并发布的内容,是由普通用户为了向其他用户传递自己的体验和感受而生产并发布的内容。UGC通常具有更强的真实性和可信度,能够吸引更多用户的关注和共鸣。如下图:

1.5 明星: #
明星账号发出来的帖子,如下图:

2. 不同声量类型识别方式: #
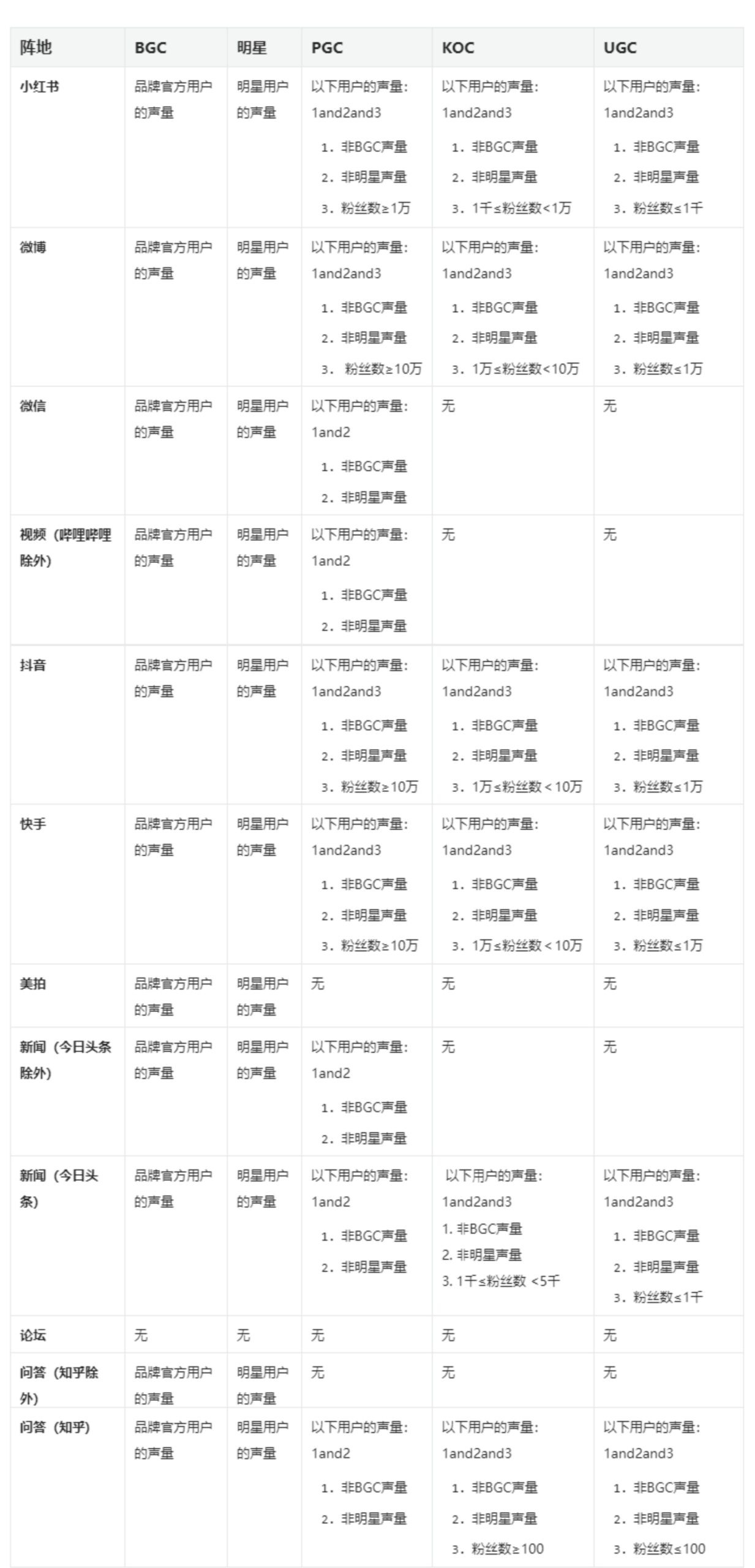
3. PGC中,不同的类型识别方式如下: #
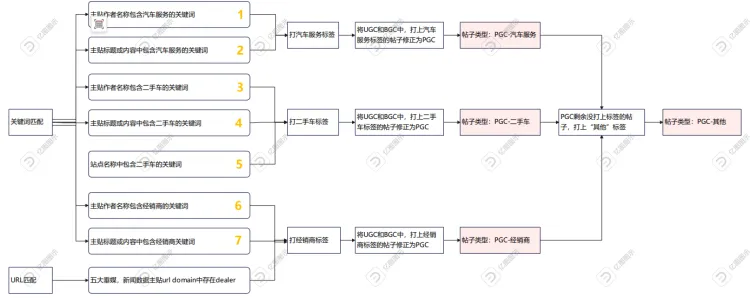
4. PGC下不同标签识别关键词: #
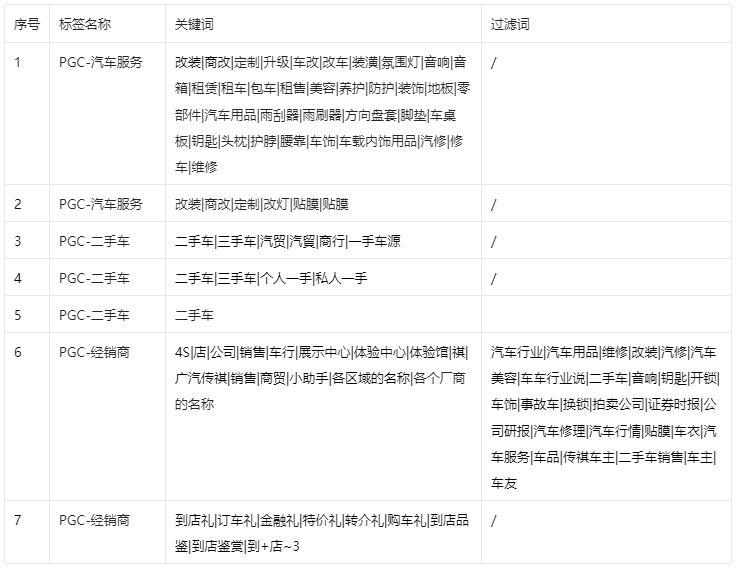
(二)声量质量 #
1. 定义: #
声量质量判断主要基于广告杂音判断算法得出的质量类型,方便用户快速挑选符合分析场景的数据样本。
2. 不同类型的定义: #
● 低质量广告
○ 低质量的广告,一般可能带有商品标题,¥,口令,价格数字,链接,优惠券,打折,加微信等信息,但其他商品描述很少
○ 二手转卖、海外代购、推销、打折促销信息折扣、优惠券,只有少量商品描述,几乎只有规格、购买链接、价格、商品标题
○ 充满火星文和表情防删除的广告
○ 微博上各种非官方抽奖
● 高质量广告
○ 有丰富产品描述、高质量广告
○ 官方发的广告、活动、新品信息
○ 软文、软广(一眼看不出是广告,看到最后才知道是广告)
● 杂音
○ 旅游推广、培训、活动报名、招聘广告
○ 任何房地产、租房、求租广告
○ 红包、转发助力
○ 分享文章、博客等没有任何实用信息的文本
○ 只有“转发微博”或只有表情
○ 微博提问,围观问题
○ 去除表情、微博名之后没有有意义文本
○ 其他明显由机器发出的文本
○ 小说
● 自发内容
○ 前面没有提到的情形都算非广告非杂音
○ 种草测评类内容、不能明显看出是广告的推荐商品信息标注为非广告非杂音
○ 自发追星微博都是非广告非杂音
(三)实体情感算法 #
1. 定义: #
分析一篇文章中,作者对这些分析对象的情感倾向。
2. 识别方式: #
如下面这个例子,通过实体情感算法,识别到作者提及探陆时情绪是正面的,因此这里针对探路记1个正面声量。负面声量的识别同理。

3. 统计方式: #
● 负面率=负面声量/声量100%
● 正面率=正面声量/声量100%
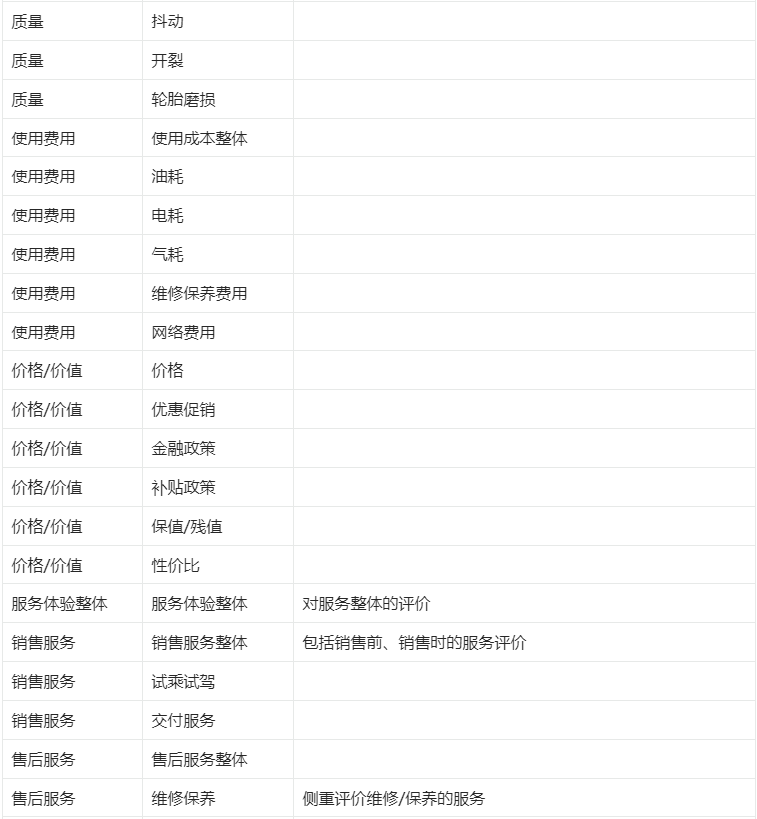
(四)三元组算法 #
1. 定义: #
分析一篇文章中,作者是通过哪些维度评价分析对象的,评价过程中有哪些情绪。各指标定义如下表:



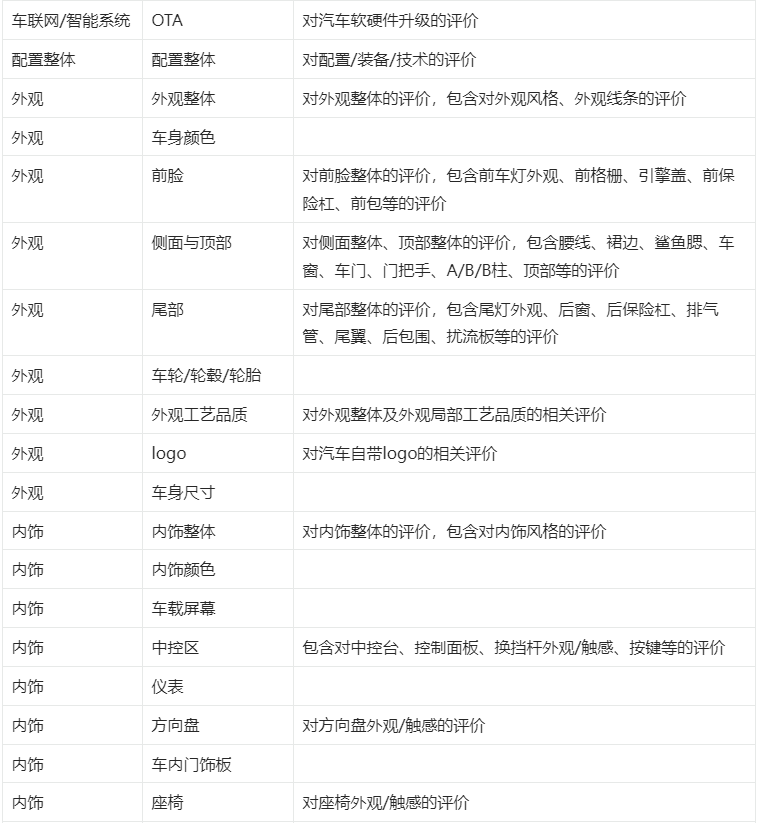

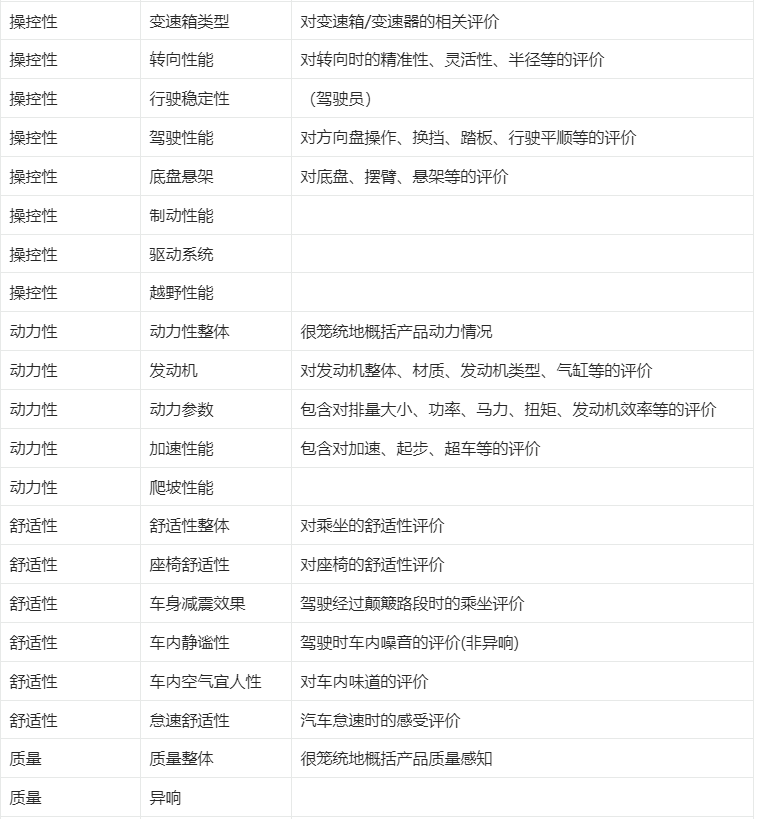

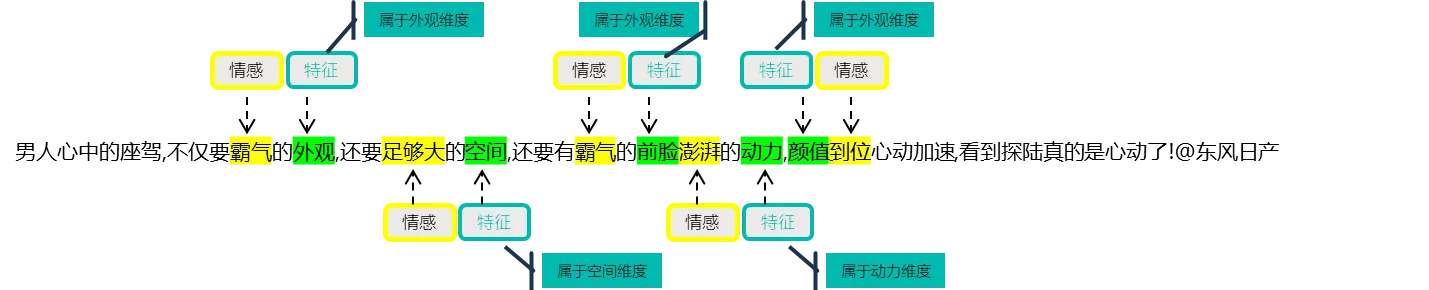
2. 识别方式: #
过智能三元组算法,找到帖子中“维度-特征词-情感表达”,并将其打上对应的标签。如下图:
(五)高频词算法 #
1. 定义: #
通过关键词提取算法,将句子中出现频率高的词语展示出来。高频词,就是指用户在表达的过程中经常使用的词语。
2. 识别方式: #

(六)聚类算法 #
1. 定义: #
将相似性高的一批文章归成一类。
2. 识别方式: #
将文本按照相似性进行聚合成多个簇,基于一个聚类假设:同簇的文本相似度较大,而不同簇的文本相似度较小。
系统数据介绍 #
一、品牌总览 #
(一)筛选器 #
1. 品牌/车系 #
● 可最多同时筛选20个品牌/车系。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。
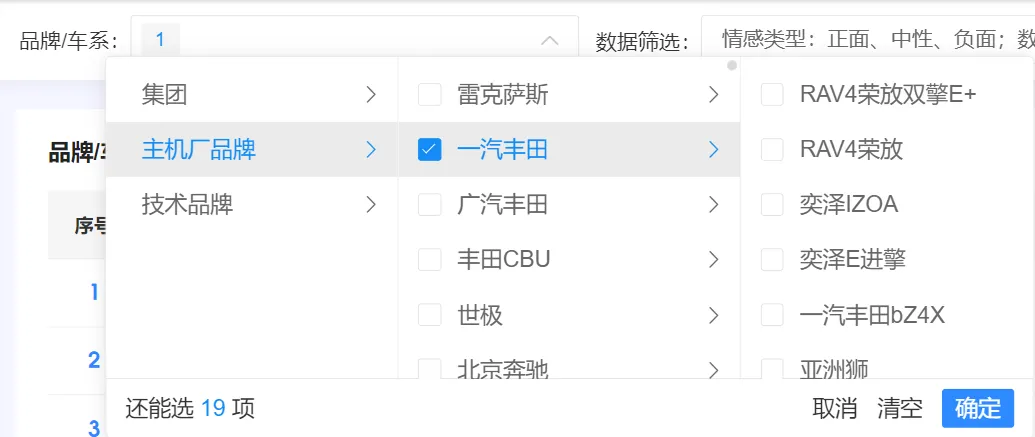
2. 数据筛选 #
● 情感类型:可筛选通过实体情感算法标识的帖子。
● 声量质量:可筛选不同质量类型的帖子。不同类型的定义请参考“五、核心算法介绍–(二)声量质量”。
● 内容包含及内容过滤:针对原文的“内容字段”,做关键词的筛选。

3. 时间筛选 #
● 时间筛选有三种模式,分别是“日期范围”“购车时长”“发售时长”,三种模式单选一种。
● 购车时长:单选。其中购车一年内的数据包含购车半年内;全部购车时长相当于筛选所有的垂媒口碑贴。购车时长的识别方式:购车日期,与今天的日期差。购车半年内:0天<今天-购买日期≤180天;购车一年内:0天<今天-购买日期≤365天;购车一年以上:今天-购买日期>365天。

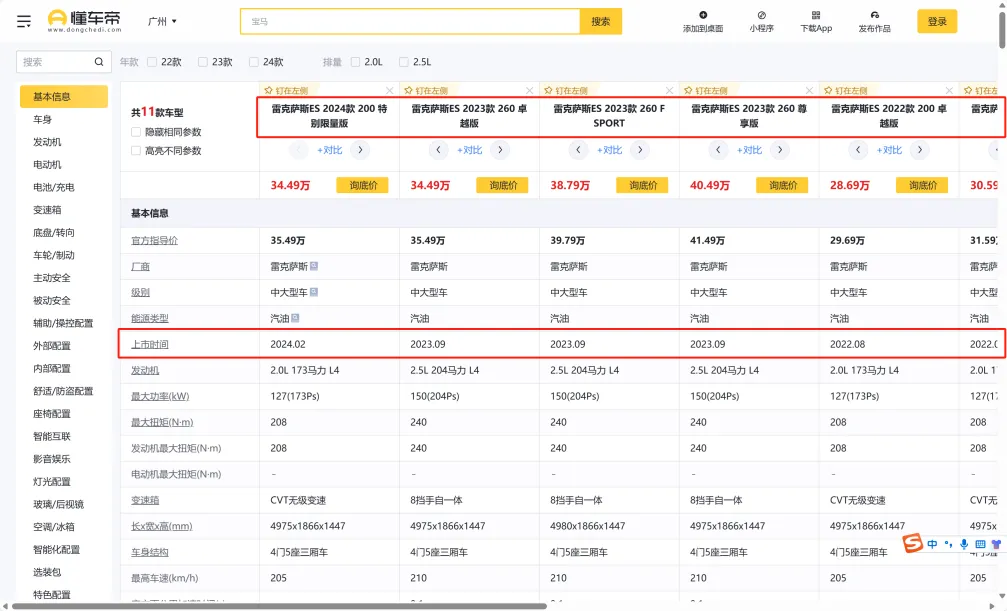
● 发售时长:单选。其中全部发售时长相当于筛选所有的垂媒口碑贴。发售时长的识别方式:采用懂车帝参数配置页上的上市日期,如下图2。

(二)品牌/车系总览 #
1. 各指标统计逻辑 #


2. 图表操作功能 #

①:同通过筛选器选择表格需要展示的指标。
②:点击可复制表格内容。
③:点击可直接打开这个品牌或者车系,对应的品牌剖析页。
④:点击三角形可针对通过该列数据进行升降序,如表格数据,按照声量字段,进行降序。
(三)指标卡 #
1. 统计逻辑 #


(四)声量分布 及 各品牌/车系下不同阵地的声量占比变化幅度 #
1. 统计逻辑 #
● 声量分布:筛选的品牌/车系,在不同阵地中的声量大小。比如华晨宝马在微博上有47,532条帖子。
● 声量占比变化幅度=所选时间周期该品牌该阵地的声量占比-上一时间周期该品牌该阵地的声量占比。 比如筛选时间为24年9月,则对比的是24年9月与24年8月声量占比之间的差值。
2. 图表操作功能 #

①:切换tab,X轴的统计维度将更新。当点击“品牌/车系”时,查看每个品牌/车系,在各个阵地的声量分布;当点击“阵地”是,查看不同的阵地,每个品牌的声量大小,如下图:

②:点击声量分布右上角的表格视图,柱状图将切换成表格的形式展现数据,并可通过右上角的下载按钮,将这个表格的数据下载到CSV文件中。如下图:

③:鼠标移动到柱状图中个各根柱子,将以悬浮框显示这根柱子背后的数据。
④:表格数据可直接下载CSV文件。
(五)互动量分布 及 各品牌/车系下不同阵地的互动量占比变化幅度 #
1. 统计逻辑 #
● 互动量分布:筛选的品牌/车系,在不同阵地中的互动量大小。比如华晨宝马在微博上有340,734个互动量。
● 互动量占比变化幅度=所选时间周期该品牌该阵地的互动量占比-上一时间周期该品牌该阵地的互动量占比。 比如筛选时间为24年9月,则对比的是24年9月与24年8月互动量占比之间的差值。
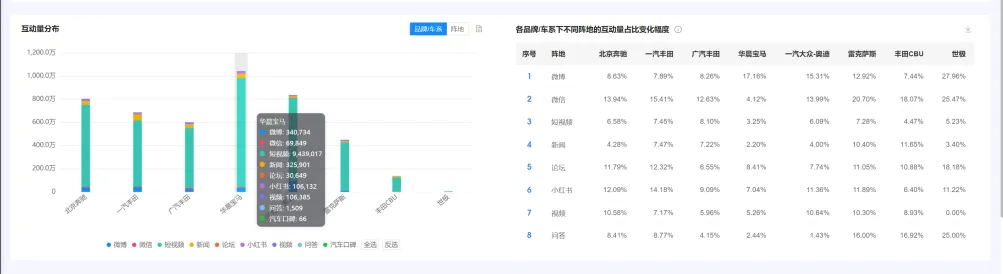
2. 图表操作功能 #
图表操作功能与“(四)声量分布 及 各品牌/车系下不同阵地的声量占比变化幅度”保持一致。
(六)各品牌/车系下不同阵地正面率表现 及 各品牌/车系下不同阵地的正面率变化幅度 #
1. 统计逻辑 #
● 正面率分布:筛选的品牌/车系,在不同阵地中的正面率大小。比如上海汽车-荣威在论坛上的正面率是23.26%。
● 正面率=正面声量÷声量
● 正面率变化幅度=所选时间周期该品牌该阵地正面率-上一时间周期该品牌该阵地正面率。 比如筛选时间为24年9月,则对比的是24年9月与24年8月正面率之间的差值。
2. 图表操作功能 #

①:鼠标在X轴上移动,将以悬浮框显示这个阵地背后的数据。
②:点击并上下滑动热力轴,右图会显示对应这个数值范围内的格子。
(七)各品牌/车系下不同阵地负面率表现 及 各品牌/车系下不同阵地的负面率变化幅度 #
1. 统计逻辑 #
● 负面率分布:筛选的品牌/车系,在不同阵地中的负面率大小。比如长安林肯在论坛上的正面率是4.27%。
● 负面率=负面声量÷声量
● 负面率变化幅度=所选时间周期该品牌该阵地负面率-上一时间周期该品牌该阵地负面率。 比如筛选时间为24年9月,则对比的是24年9月与24年8月负面率之间的差值。
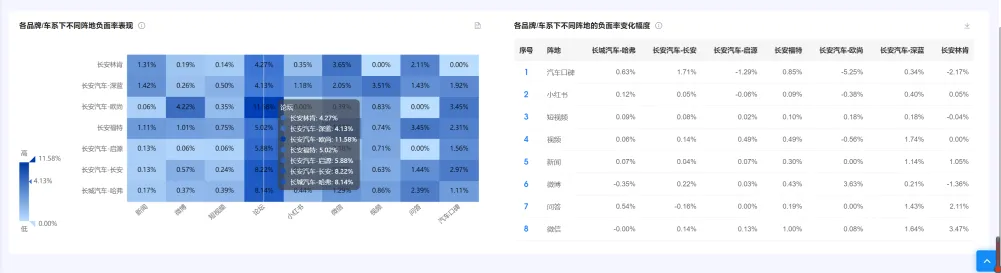
2. 图表操作功能 #
图表操作功能与“(六)声量分布 及 各品牌/车系下不同阵地的声量占比变化幅度”保持一致。
二、品牌剖析 #
(一)筛选器 #
1. 品牌/车系 #
● 单选。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。
2. 数据筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>2.数据筛选“保持一致。
3. 时间筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>3.时间筛选“保持一致。
(二)指标卡 #
1. 统计逻辑 #
1.1 品牌/车系筛选厂商的时候,如下图。
以声量指标卡为例,互动量、负面率、作者数、站点数的统计逻辑与声量指标卡的保持一致。

● 声量:品牌/车系在筛选条件下(数据筛选+时间筛选),帖子数量。
● 同比:声量同比=(本期声量-去年同期声量)÷去年同期声量
● 环比:声量环比=(本期声量-上期声量)÷上期声量
● VS.市场最高:先找到系统中声量最高的品牌,然后与这个品牌的声量值进行对比。VS.市场最高=(所选品牌的声量-声量最高的品牌的声量)÷声量最高的品牌的声量。这个值看的是所选品牌,对比市场中声量最高的品牌,声量差距有多大。
● VS.市场均值:先计算系统中所有品牌的声量均值,然后与均值进行对比。VS.市场均值=(所选品牌的声量-市场均值)÷市场均值。这个值看的是所选品牌,对比市场均值,声量差距有多大。
● 作者数:品牌/车系在筛选条件下(数据筛选+时间筛选),不重复的账号数量。
● 站点数:品牌/车系在筛选条件下(数据筛选+时间筛选),站点数量。比如懂车帝、汽车之家算两个站点。
(三)各阵地核心指标变化趋势 #
1. 统计逻辑 #
以声量为例,互动量、情感、作者数的统计逻辑与声量保持一致。
● 均值:每日个真滴声量值加总,然后再计算这个时间段的均值。

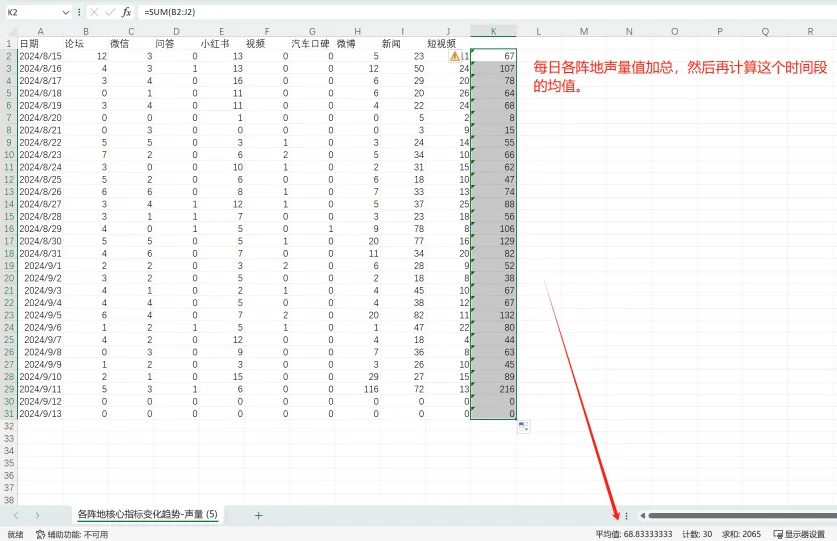
2. 图表操作逻辑 #

①:切换tab,X轴的统计维度将更新。当点击“声量”时,查看各个阵地的声量变化趋势;当点击“互动量”时,查看各阵地的互动量变化趋势;情感和作者数同理。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:鼠标随着X轴移动,将以悬浮框形式展示当天各个阵地的数据,以及总数。
④:图例的全选和反选:
● 任何一个图例都可以单独点击,比如单击论坛后,图例置灰,趋势图将不展示该阵地的数据;再一次单击论坛后,图例恢复颜色,趋势图将展示该阵地的数据。如下图:

● 全选是指全部图例对应的阵地都选上,趋势图中呈现所有阵地的数据。如下图:

● 反选是指统一将所有图例都置灰,趋势图将不展示这些阵地的数据。如下图:

(四)各阵地分布 #
1. 统计逻辑 #
● 声量:品牌/车系在筛选条件下(数据筛选+时间筛选),在不同阵地的帖子数量。
● 互动量:品牌/车系在筛选条件下(数据筛选+时间筛选),在不同阵地的互动量。
● 平均互动量:平均互动量=互动量/声量。表示不同的阵地,平均一条帖子能带来多少互动。
● 作者数:品牌/车系在筛选条件下(数据筛选+时间筛选),在不同阵地的账号数量。
2. 图表操作逻辑 #


①:下拉菜单选择看数据的维度。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:鼠标放置到不同的柱子上,将以悬浮框形式展示这个阵地的数据。
④:点击柱子,可联动该页的其他图表,呈现只是这个阵地的数据结果。
(五)声量类型分布 #
1. 统计逻辑 #
● 不同类型的声量识别模式,请参考“五、核心算法介绍–>(一)声量类型”。
● 不同类型声量占比(如41.73%)=该类型声量(如1061610)/声量(2225111),如下图。
● 不同诶行作者数占比统计逻辑同上。

2. 图表操作逻辑 #
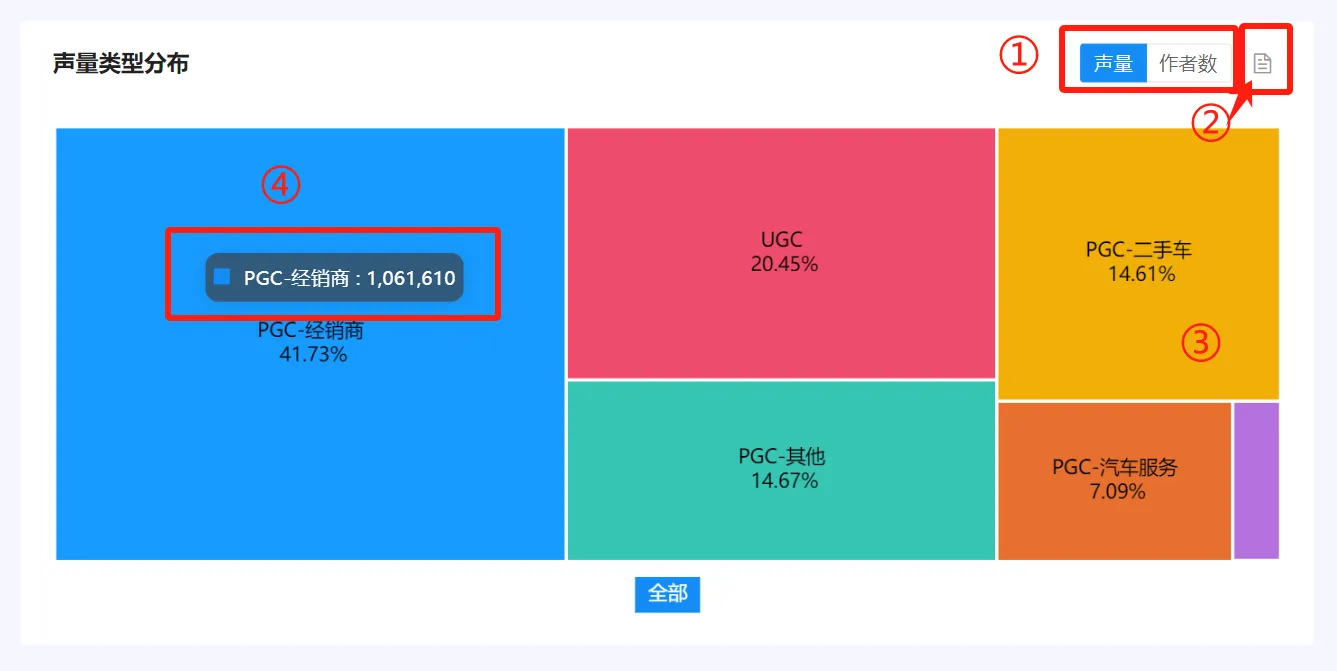
①:切换tab,统计维度将更新。当点击“声量”时,查看各个类型的声量占比;当点击“作者数”时,查看类型的作者数占比。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:点击图表任何一块,比如黄色的PGC-二手车,可联动页面其他图表显示这种声量类型的数据结果。
④:鼠标放置到不同的色块,将以悬浮框形式展示这种类型的数据。
(六)情感占比分布 #
1. 统计逻辑 #
● 不同情感类型通过实体情感算法进行识别。实体情感算法介绍请参考“五、核心算法介绍–>(三)实体情感”。
● 不同情绪声量占比(如1.62%)=负面声量(如36113)/声量(2225111),如下图。
2. 图表操作逻辑 #
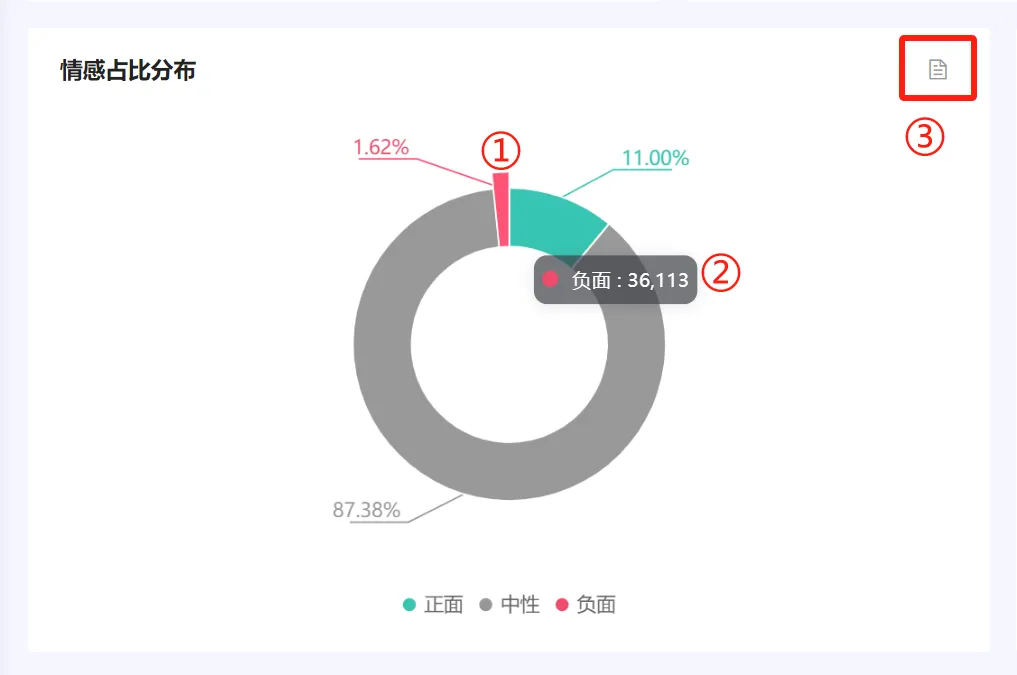
①:点击图表任何一块,比如红色的负面,可联动页面其他图表显示负面的数据结果。
②:鼠标放置到不同的色块,将以悬浮框形式展示这种类型的数据。
③:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(七)词云图 #
1. 统计逻辑 #
● 高频词的结果采用高频词算法识别得出。高频词算法介绍请参考“五、核心算法介绍–>(五)高频词算法”。
● 词语对应的声量(如下图370259),是指包含了这个高频词的帖子有370259条。
● 话题名称统计微博、抖音、小红书、微信视频号四个站点,带“#”的话题帖子量。
● 词云图关键词的字体大小由声量决定,声量越大字体越大;每个词云图固定放置声量最大的头70个关键词。

2. 图表操作逻辑 #

①:下拉菜单选择查看不同类型的词云图。
②:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上角的“还原隐藏关键词”。
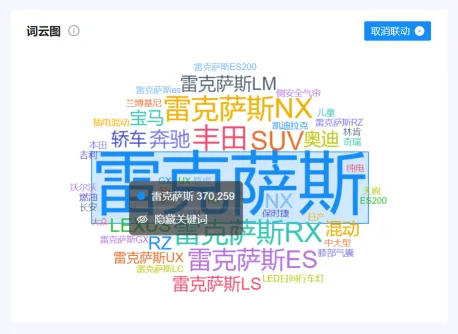
③:“放大”,点击后整个词云图将放大显示,如下图:

④:点击“设置词云图形状”,页面右侧弹出设置栏。选择并点击其中一个形状,如“汽车”,词云图将替换成相应的样式。如下图:
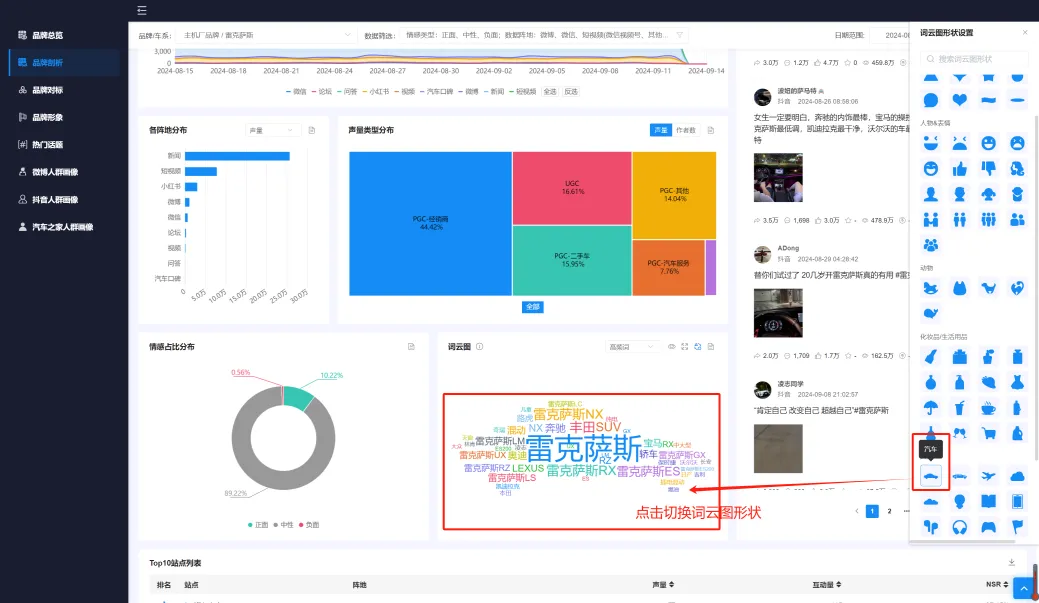
⑤:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
⑥:鼠标放置到不同的关键词上,将以悬浮框形式展示这种类型的数据。
⑦:点击关键词,可联动页面其他图表显示该关键词的数据结果。
(八)TOP10站点列表 #
1. 统计逻辑 #
● 对应到具体站点,以及阵地,有多少声量(帖子量),这些帖子带来了多少互动量,以及这些帖子通过实体情感算法识别出情绪之后计算出来的NSR。帖子NSR。
● 声量、互动量、NSR统计方式,参考“三、图表介绍–>【品牌总览】–>(二)各指标统计逻辑”。
2. 图表操作逻辑 #
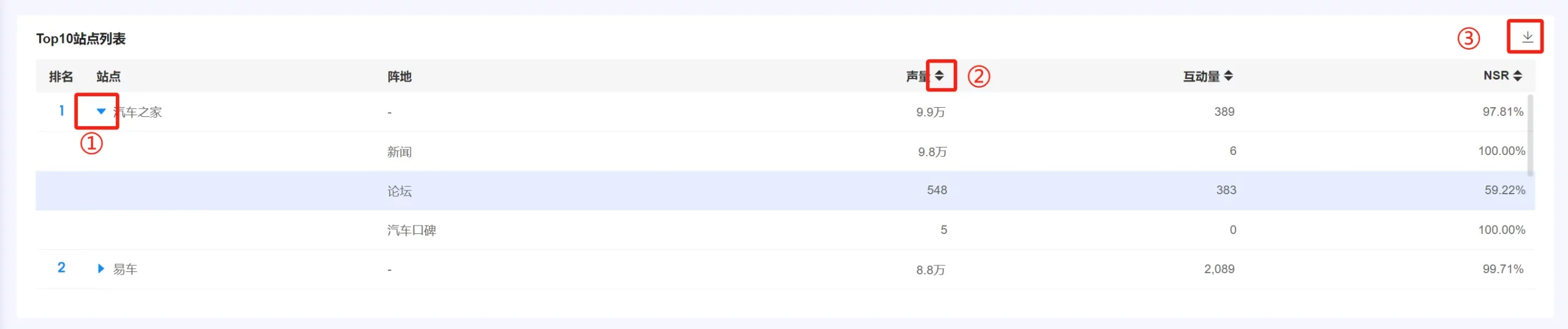
①:点击三角形展开或收起这个站点的信息,展开后,可具体查看这个站点在不同阵地类型上的情况,比如汽车之家,新闻版块的声量、互动量、NSR。同样的站点,不同阵地的声量和互动量加总得到站点这一行(第一行,汽车之家)的声量和互动量。
②:点击字段的升降序按钮,可针对该字段进行数据排序。默认按声量降序排列。
③:点击右上角下载按钮,可通过CSV文件导出这个表的数据。
④:点击任何一行,可联动页面其他图表显示该数据源的数据结果。
⑤:鼠标放置表格中并往下滚动,可查看其他排名的数据结果。
(九)TOP10活跃作者 #
1. 统计逻辑 #
● 对应到具体每个作者,以及在不同站点的账号里,有多少声量(帖子量),这些帖子带来了多少互动量,以及这些帖子通过实体情感算法识别出情绪之后计算出来的NSR。帖子NSR。
● 声量、互动量、NSR统计方式,参考“三、图表介绍–>【品牌总览】–>(二)各指标统计逻辑”。
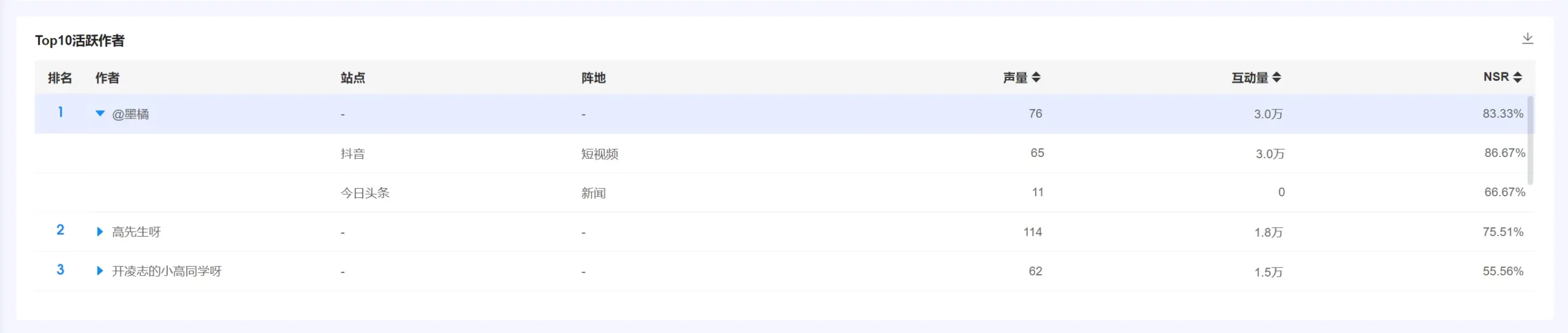
2. 图表操作逻辑 #
● 操作方式与”TOP10站点列表“保持一致,请参考”三、图表介绍–>【品牌剖析】–>(八)TOP10站点列表–>2.图表操作逻辑“。
(十)TOP10事件列表 #
1. 统计逻辑 #
● 通过聚类算法,得到每个事件。聚类算法介绍请参考“五、核心算法介绍–>(六)聚类算法”。
● 事件名称、事件事件展示这个事件中互动量最高的帖子的标题、发帖时间;声量、互动量为对应每个事件,所有帖子的声量,以及对应的互动量总和。
● 平均互动量=互动量÷声量
● 声量、互动量统计方式,参考“三、图表介绍–>【品牌总览】–>(二)各指标统计逻辑”。
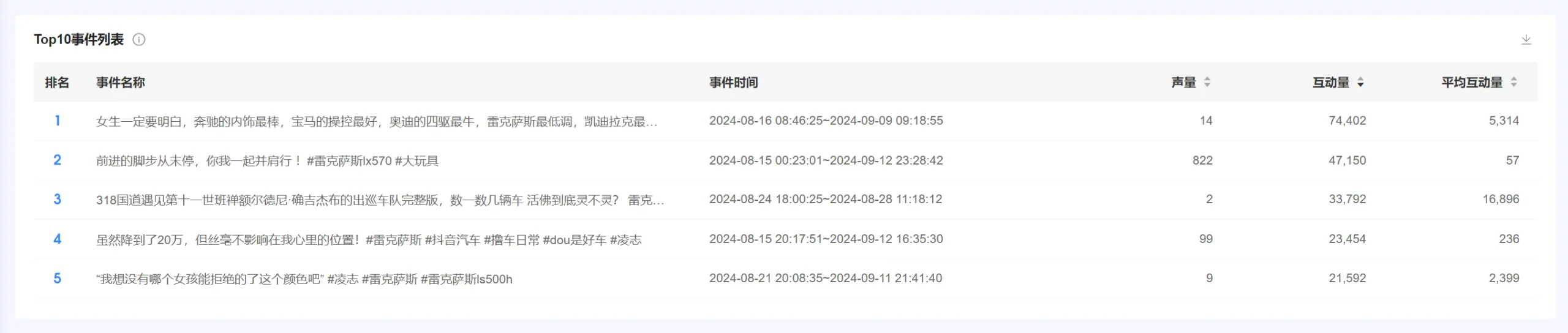
2. 图表操作逻辑 #
● 操作方式请参考”三、图表介绍–>【品牌剖析】–>(八)TOP10站点列表–>2.图表操作逻辑“中的②、③、④、⑤。
(十一)一级维度提及率 #
1. 统计逻辑 #
● 通过三元组算法,识别得出每个维度的声量。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。
● 维度提及率=提及维度的声量/所有维度的声量之和100%。1个帖子中多次提到某个维度也只计算一次。
● 维度正面提及率=维度正面的声量/所有正面维度的声量之和100%(注:正面可通过顶栏筛选器情感类型控制)
● 维度负面提及率=维度负面的声量/所有负面维度的声量之和*100%(注:负面可通过顶栏筛选器情感类型控制,如下图)

2. 图表操作逻辑 #
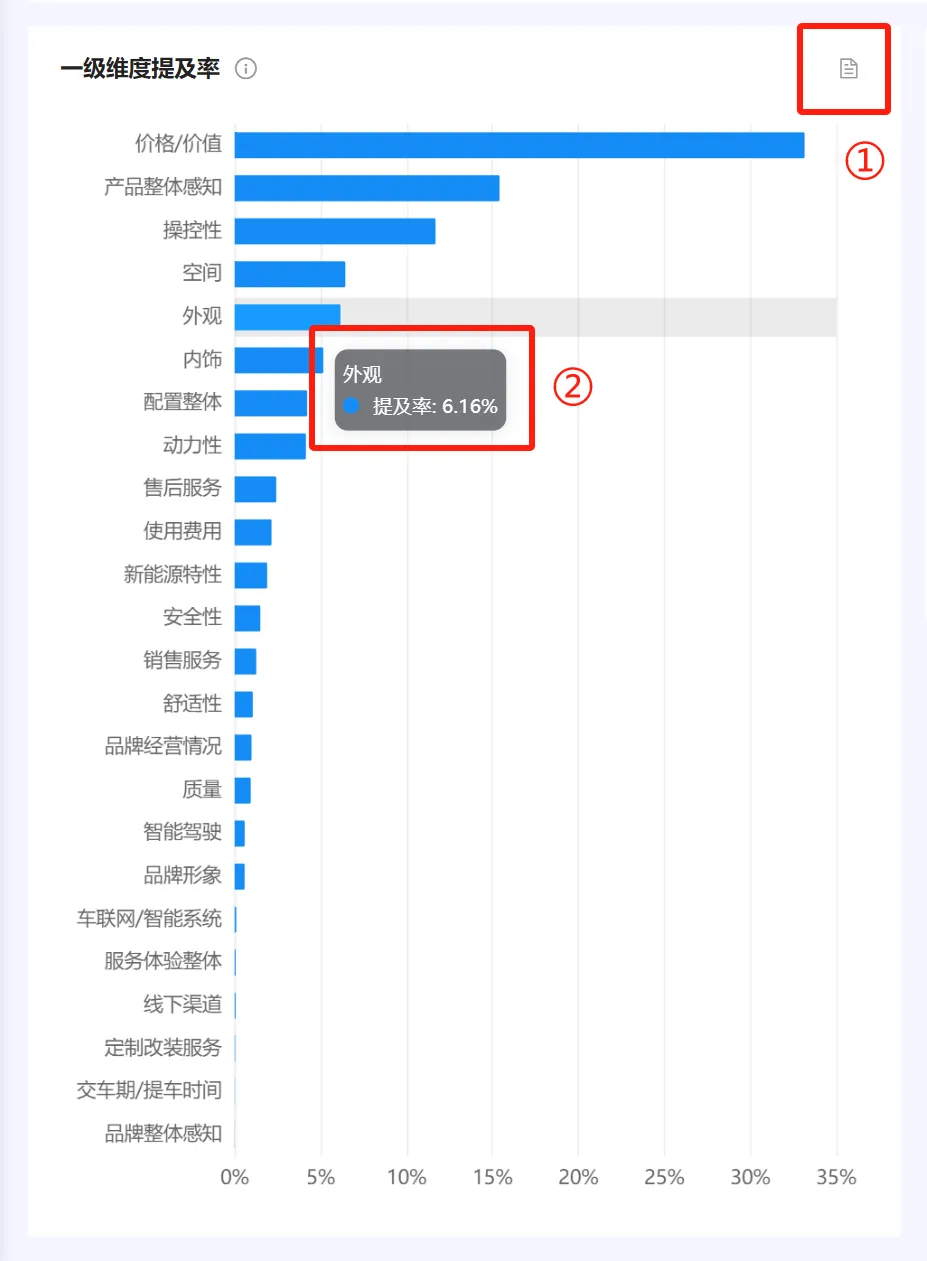
①:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
②:鼠标放置到不同的柱子上,将以悬浮框形式展示这个维度的数据。
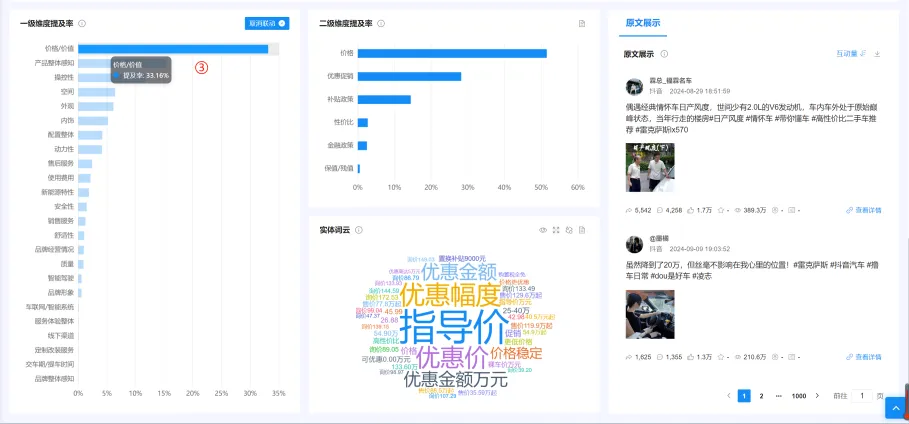
③:点击柱子,可联动右边的几个图表,展示这个一级维度的详细结果。
(十二)二级维度提及率 #
1. 统计逻辑 #
● 通过三元组算法,识别得出每个维度的声量。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。
● 维度提及率=提及维度的声量/所有维度的声量之和100%。1个帖子中多次提到某个维度也只计算一次。
● 维度正面提及率=维度正面的声量/所有正面维度的声量之和100%(注:正面可通过顶栏筛选器情感类型控制,和前面“一级维度提及率”的方式一致)
● 维度负面提及率=维度负面的声量/所有负面维度的声量之和*100%(注:负面可通过顶栏筛选器情感类型控制,和前面“一级维度提及率”的方式一致)
2. 图表操作逻辑 #
● 操作方式请参考”三、图表介绍–>【品牌剖析】–>(十一)一级维度提及率–>2.图表操作逻辑“。
(十三)实体词云 #
1. 统计逻辑 #
● 通过三元组算法,识别得出实体词,也就是特征+情感对。用来快速了解用户在编辑有关这个分析对象的帖子时,都关注了哪些方面。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。
● 词语对应的声量(如下图64393),是指这个实体词对应的帖子有64383条。
● 词云图关键词的字体大小由声量决定,声量越大字体越大;每个词云图固定放置声量最大的头70个关键词。

2. 图表操作逻辑 #

● 图表中对应位置的功能,请参考”三、图表介绍–>【品牌剖析】–>(七)词云图–>2.图表操作逻辑“。
(十四)原文展示 #
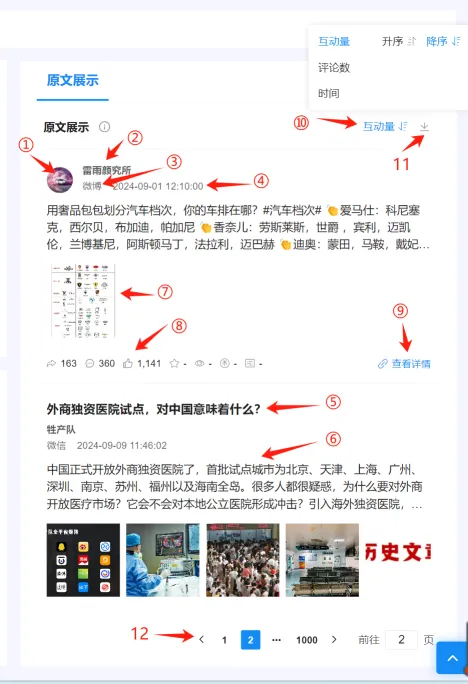
①:发布这条帖子的账号头像。
②:发布这条帖子的账号名称。
③:发布这条帖子的站点。
④:发布这条帖子的时间。
⑤:这条帖子的标题(注:不是所有站点都有标题,比如微博、抖音这些站点的帖子没标题)。
⑥:这条帖子的内容。
⑦:这条帖子附带的图片或视频。
⑧:这条帖子的互动量指标(注:每个站点对应的互动量指标有哪些内容,更新机制请参考”四、核心指标定义–>(二)互动量–>2.互动量更新机制“)。
⑨:点击“查看详情”可打开这条帖子对应的网页链接,如下图:
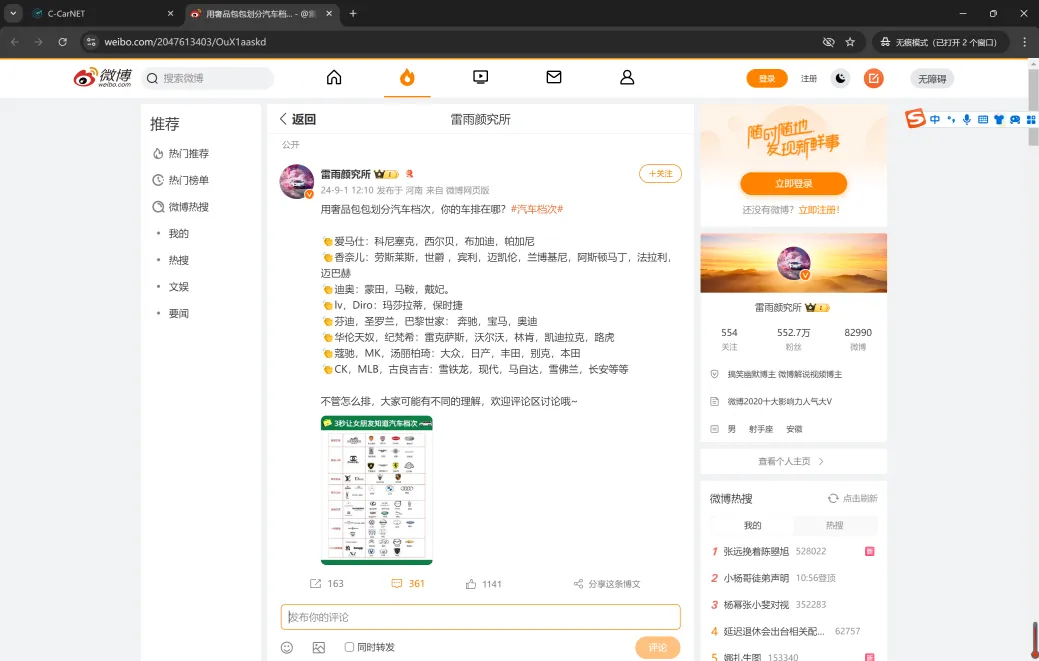
⑩:原文展示过程中,可以根据互动量大小,升降序排列;也可以按照评论数,或者按照时间进行排序展示。
- 点击右上角下载按钮,可通过CSV文件导出头200条原文。
- 点击页面进行翻页,或者填写想要具体到达的页面,展示该页的原文。
- 点击页面中的图表,可关键展示对应维度的原文。
三、品牌对标 #
(一)筛选器 #
1. 品牌/车系 #
● 单选。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。2. 对标品牌 #
● 多选,最多可选4个对标对象。
3. 数据筛选 #
● 与【品牌总览】-筛选器-数据筛选保持一致。
4. 时间筛选 #
● 与【品牌总览】-筛选器-时间筛选保持一致。
(二)品牌热度表现 及 品牌热度趋势对比 #
1. 统计逻辑 #
● 声量:与分析对象相关的帖子量总和,若在同一条帖子被提及多次,声量记1。 主贴、转发或者评论都分别计为1个声量。
● 互动量:针对分析对象被提及文本的所有互动指标之和,包括转发数/评论数/点赞数/收藏数等。2. 图表操作功能 #

①:点击字段的升降序按钮,可针对该字段进行数据排序。默认按声量降序排列。
②:点击右上角下载按钮,可通过CSV文件导出头表格的数据。
③:切换tab,Y轴的统计维度将更新。当点击“声量"时,查看每个品牌/车系,在各个阵地的声量分布;当点击“阵地”是,查看不同的阵地,每个品牌的声量大小。
④:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
⑤:鼠标随着X轴移动,将以悬浮框形式展示当天各个阵地的数据,以及总数。
⑥:功能介绍请参考”【品牌剖析】–>(三)各阵地核心指标变化趋势–>2.图表操作逻辑–>④“。
(三)品牌情感表现 及 品牌情感趋势对比 #
1. 统计逻辑 #
● 正面率:正面率=正面声量÷声量。正面声量采用实体情感算法获得;实体情感算法介绍请参考“五、核心算法介绍–>(三)实体情感算法”。
● 负面率:负面率=负面声量÷声量。负面声量采用实体情感算法获得;实体情感算法介绍请参考“五、核心算法介绍–>(三)实体情感算法”。
● NSR:请参考”【品牌总览】–>(二)品牌/车系总览–>1.各指标统计逻辑“。
2. 图表操作功能 #

①:点击字段的升降序按钮,可针对该字段进行数据排序。默认按正面率降序排列。
②:点击右上角下载按钮,可通过CSV文件导出头表格的数据。
③:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
④:点击图例,堆积柱状图可自由选择呈现的数据维度。图例为灰色的时候数据不显示,图例有颜色的时候数据显示。
⑤:鼠标随着X轴移动,将以悬浮框形式展示每根柱子背后的数据。
(四)各阵地品牌负面率对比 及 各阵地品牌热度对比 #
1. 统计逻辑 #
● 负面率:负面率=负面声量÷声量。负面声量采用实体情感算法获得;实体情感算法介绍请参考“五、核心算法介绍–>(三)实体情感算法”。
● 声量:与分析对象相关的帖子量总和;声量识别介绍请参考“系统数据介绍–>四、核心指标定义–>(一)声量”。
● 互动量:针对分析对象被提及文本的所有互动指标之和,包括转发数/评论数/点赞数/收藏数等;互动量识别介绍请参考“系统数据介绍–>四、核心指标定义–>(二)互动量”。
2. 图表操作功能 #
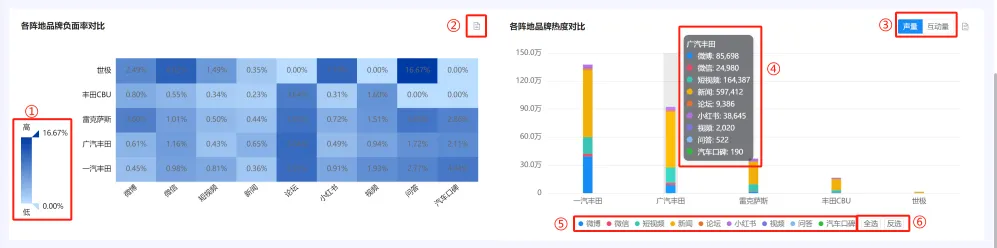
①:点击并上下滑动热力轴,右图会显示对应这个数值范围内的格子。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:切换tab,Y轴的统计维度将更新。当点击“声量"时,查看每个品牌/车系,在各个阵地的声量分布;当点击“互动量"时,查看每个品牌/车系,在各个阵地的互动量分布。
④:鼠标随着X轴移动,将以悬浮框形式展示每根柱子背后的数据。
⑤:点击图例,堆积柱状图可自由选择呈现的数据维度。图例为灰色的时候数据不显示,图例有颜色的时候数据显示。
⑥:功能介绍请参考”【品牌剖析】–>(三)各阵地核心指标变化趋势–>2.图表操作逻辑–>④“。
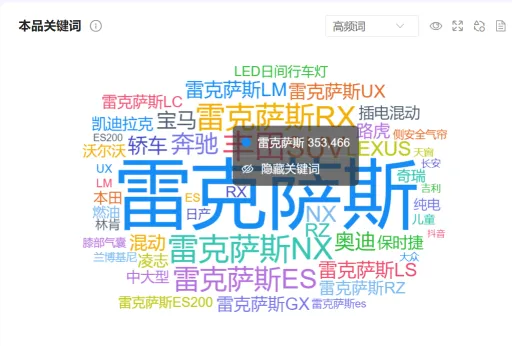
(五)本品/竞品关键词 及 品牌相关关键词对比 #
1. 统计逻辑 #
● 高频词:高频词的结果采用高频词算法识别得出。高频词算法介绍请参考“五、核心算法介绍–>(五)高频词算法”。词语对应的声量(如下图353466),是指包含了这个高频词的帖子有353466条。
● 实体词云:通过三元组算法,识别得出实体词,也就是特征+情感对。用来快速了解用户在编辑有关这个分析对象的帖子时,都关注了哪些方面。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。括号中的内容是实体词对应的一级维度,括号外是实体词,如下图中“豪华”这个实体词,对应的维度是“产品整体感知”。

● 正面词云:将“实体词云”中,代表正面情绪的实体词展示出来。用来快速了解用户在评价有关这个分析对象的帖子时,主要的正面情绪都分布在哪些方面。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。
● 负面词云:将“实体词云”中,代表负面情绪的实体词展示出来。用来快速了解用户在评价有关这个分析对象的帖子时,主要的负面情绪都分布在哪些方面。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。
● 词云图关键词的字体大小由声量决定,声量越大字体越大;每个词云图固定放置声量最大的头70个关键词。
● 品牌相关关键词对比:左边本竞品关键词-高频词结果中,声量头10个共同提及的关键词,外圆(灰色圈)大小无实质业务含义,内圆大小代表声量大小(其他颜色的圈)。比如下图:
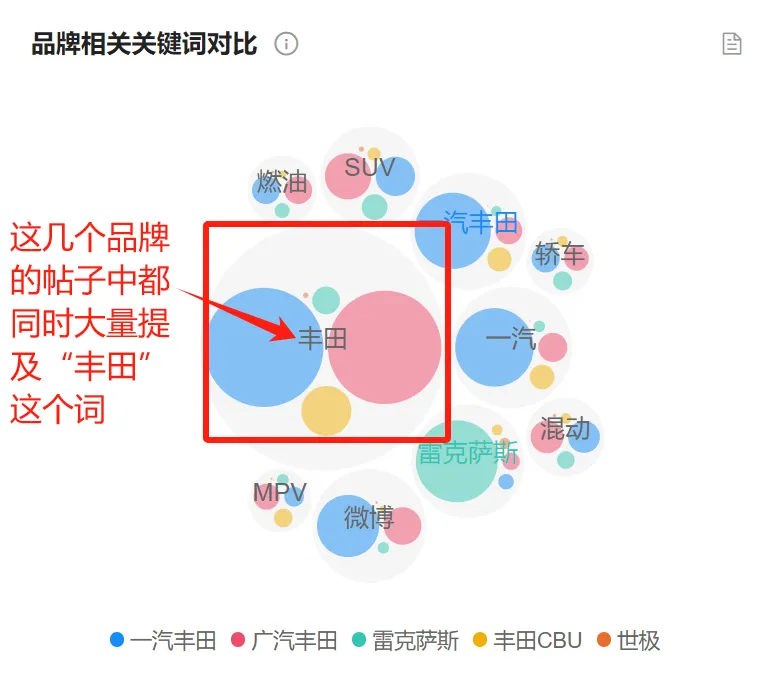
2. 图表操作功能 #

①:通过下拉筛选器,查看不同类型的词云图。
②:通过下拉筛选器,筛选需要对比查看的某个竞争对手的词云图。
③:⿏标放置到不同的关键词上,将以悬浮框形式展示这种类型的数据。
④:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键 词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上⻆的“还原隐藏关键词”。
⑤:“放⼤”,点击后整个词云图将放⼤显示。
⑥:点击“设置词云图形状”,⻚⾯右侧弹出设置栏。选择并点击其中⼀个形状,如“汽⻋”,词云图将替 换成相应的样式。
⑦:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②⼀致。
⑧:点击灰色底的圆圈,可放大该区域的显示。
⑨:点击图例,可自由选择呈现的数据维度。图例为灰色的时候,上图对应颜色的圆圈不显示,图例有颜色的时候显示。
(六)原文展示 #
具体功能请参考“系统图表介绍–>二、品牌剖析–>(十四)原文展示”。
四、品牌形象 #
(一)筛选器 #
1. 品牌/车系 #
● 单选。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。
2. 数据筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>2.数据筛选“保持一致。
3. 时间筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>3.时间筛选“保持一致。
(二)品牌形象 #
1. 统计逻辑 #
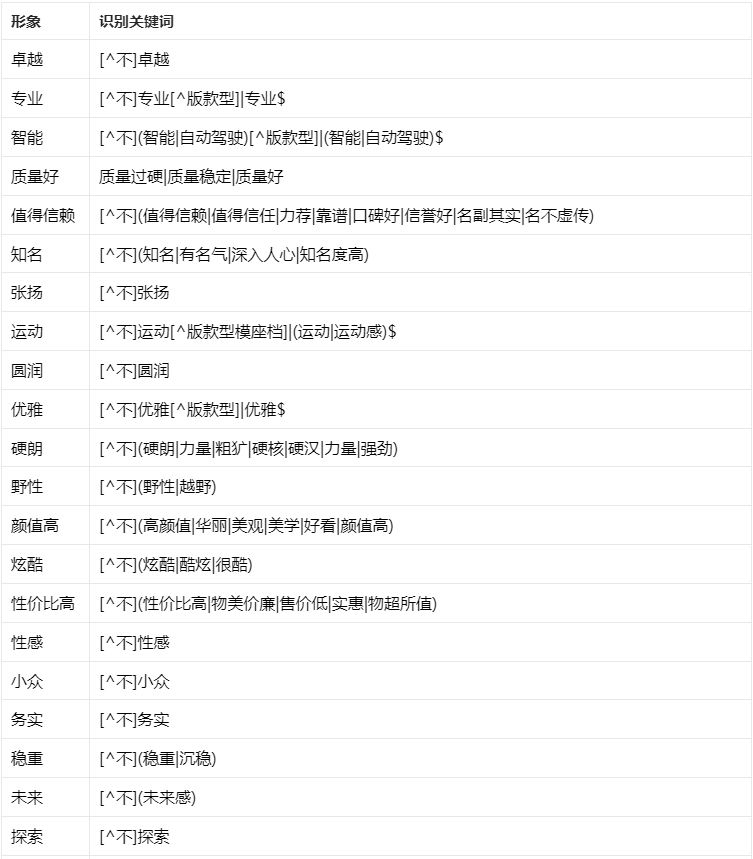
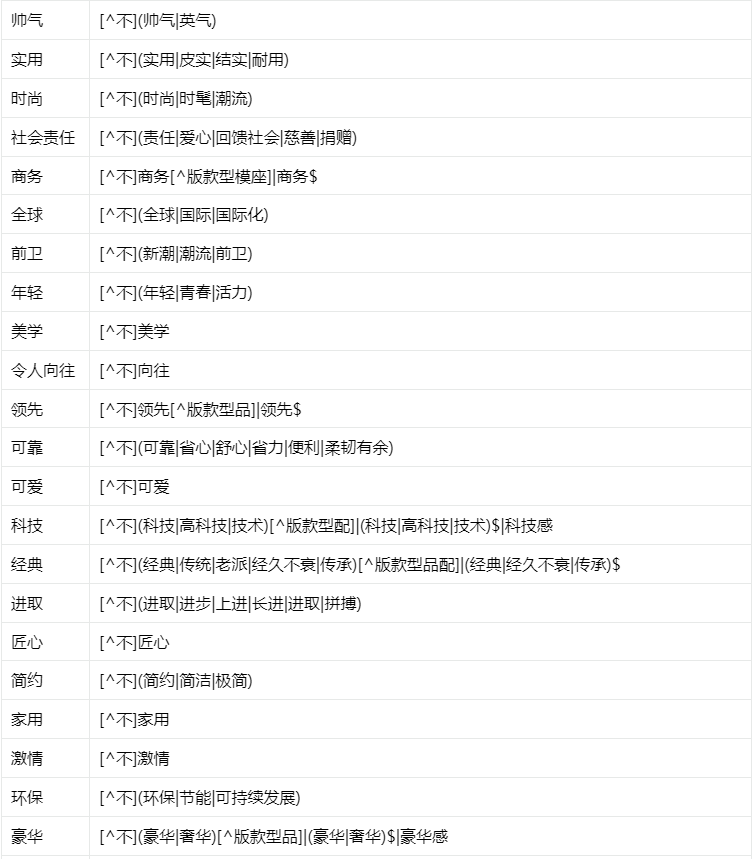
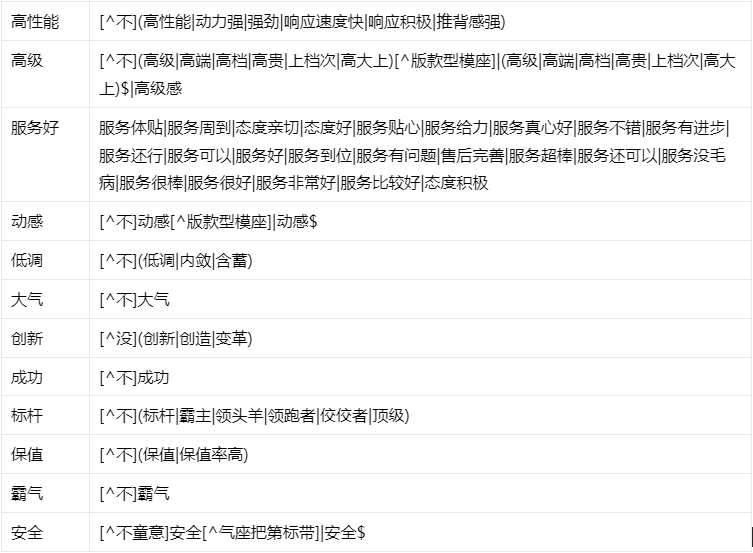
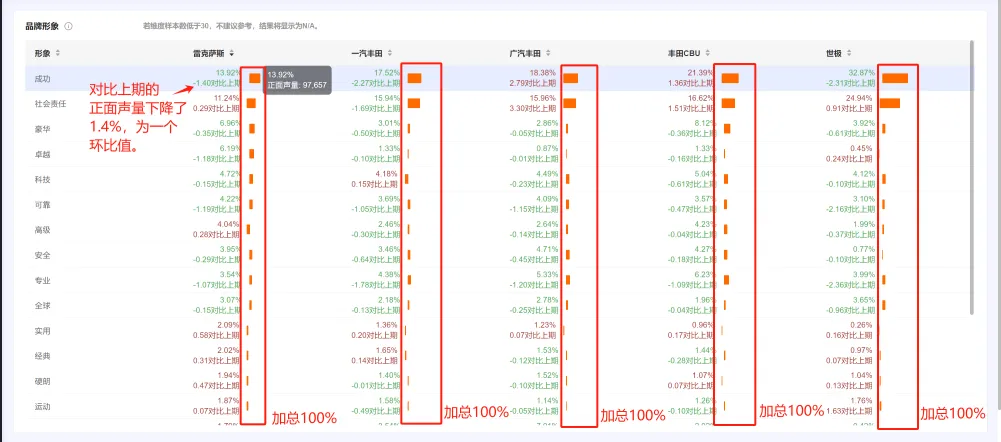
● 品牌形象的识别根据品牌形象码表找到不同的形象表达,然后以形象表达为中心前后一句话之内找到对应的品牌/车系,以此作为该品牌的形象。如下图。

品牌形象识别码表请参考下表:
● 若某个形象维度与品牌/车系同时出现的帖子量少于30条,结果将显示为N/A。
● 每个品牌,各个维度的形象声量占比=该品牌形象维度声量/该品牌所有形象声量总和。比如下图:
2. 图表操作功能 #
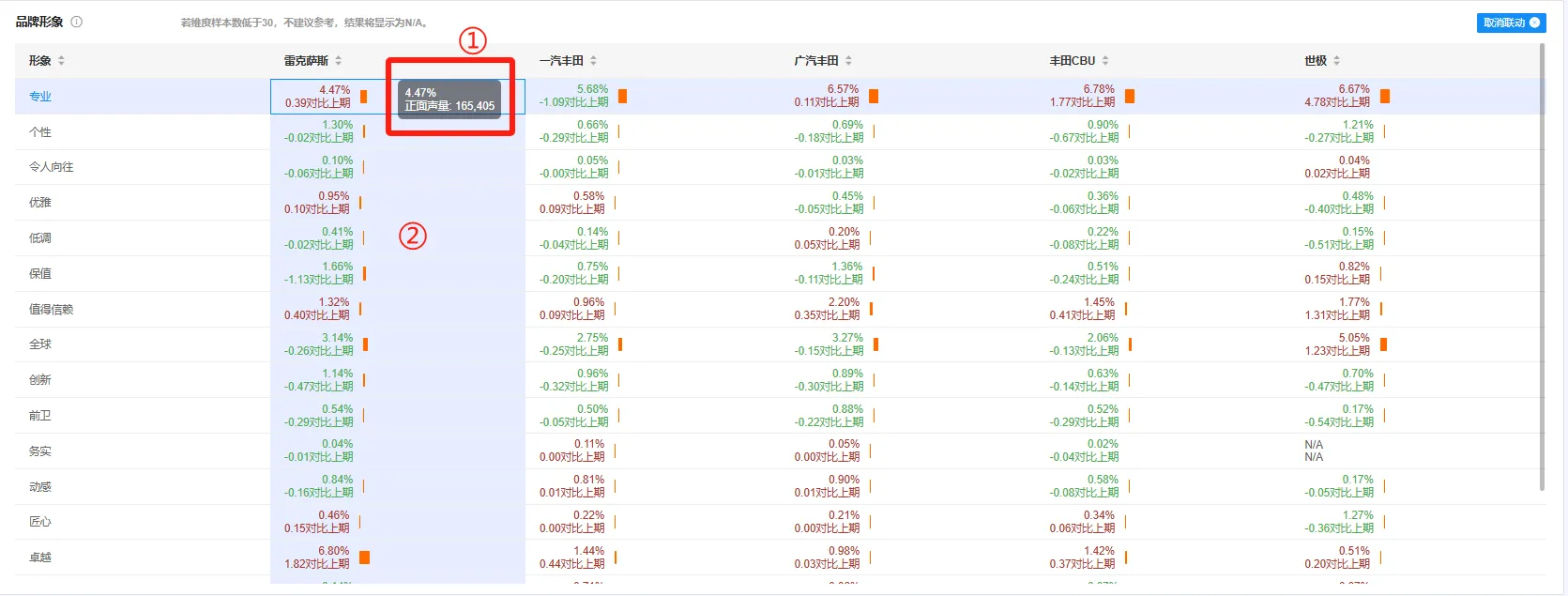
①:鼠标放置到不同的单元格中,将以悬浮框形式展示这个单元格背后的声量。
②:点击“雷克萨斯”与“专业”交集的这个单元格,将联动页面中其他图表展示同时包含“雷克萨斯”和“专业”关键词的这些帖子的数据结果。
(三)飙升热词 及 词云图 #
1. 统计逻辑 #
● 飙升热词统计的是词云图中“高频词”对应的结果,相对于上期,或同期来说,飙升率最高的词是哪些,这些词在对应的筛选条件下,声量是多少。该图能快速看到哪些关键词是突然出现的。
● VS上期飙升率=(该词本期声量-该词上期声量)÷该词上期声量100%
● VS同期飙升率=(该词本期声量-该词去年同期期声量)÷该词去年同期声量100%
● 高频词的结果采用高频词算法识别得出。高频词算法介绍请参考“五、核心算法介绍–>(五)高频词算法”。
● 实体词云:通过三元组算法,识别得出实体词,也就是特征+情感对。用来快速了解用户在编辑有关这个分析对象的帖子时,都关注了哪些方面。三元组算法介绍请参考“五、核心算法介绍–>(四)三元组算法”。括号中的内容是实体词对应的一级维度,括号外是实体词。
2. 图表操作功能 #
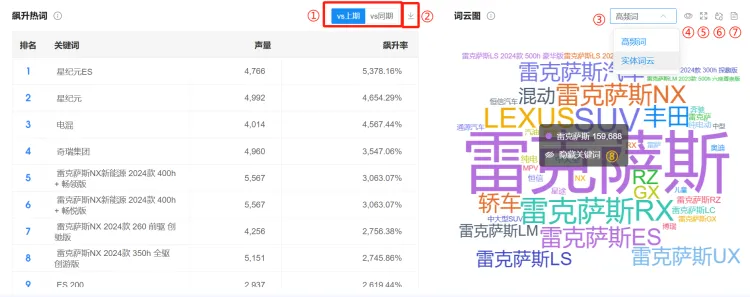
①:tab键切换看不同时间对比维度的数据。
②:点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。
③:通过下拉筛选器,查看不同类型的词云图。
④:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键 词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上⻆的“还原隐藏关键词”。
⑤:“放⼤”,点击后整个词云图将放⼤显示。
⑥:点击“设置词云图形状”,⻚⾯右侧弹出设置栏。选择并点击其中⼀个形状,如“汽⻋”,词云图将替 换成相应的样式。
⑦:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②⼀致。
⑧:⿏标放置到不同的关键词上,将以悬浮框形式展示这个关键词的声量。
(四)原文展示 #
具体功能请参考“系统图表介绍–>二、品牌剖析–>(十四)原文展示”。
五、热门话题 #
(一)筛选器 #
1. 品牌/车系 #
● 单选。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。
2. 数据筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>2.数据筛选“保持一致。
3. 时间筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>3.时间筛选“保持一致。
(二)话题列表 #
1. 统计逻辑 #
● 话题:微博、抖音、微信视频号三个站点中,带#的话题声量。如下图位置,#老车翻新、#雷克萨斯570,#发动机大修,#一镜到底,#解压,都分别是属于抖音这个站点中的话题。分别统计这些话题在抖音站点,雷克萨斯数据中有多少帖子带了这些话题。微博、微信视频号也同样道理。

● 品牌:这个话题对应是哪个品牌或车系的原文中使用到。
● 声量:涉及到该话题的帖子量。
● 互动量:涉及到该话题的帖子中,互动指标的加总。不同平台的互动指标定义请参考”核心指标定义–>(二)互动量–>2. 互动量更新机制“。
● 正面率:涉及到该话题的声量中,正面声量的占比。正面率=正面声量/声量。正面声量由实体情感算法识别得出,实体情感介绍请参考”核心算法介绍–>(三)实体情感算法“。
● 负面率:涉及到该话题的声量中,负面声量的占比。负面率=负面声量/声量。负面声量由实体情感算法识别得出,实体情感介绍请参考”核心算法介绍–>(三)实体情感算法“。
● NSR:涉及到该话题的所有声量的净情感度。NSR=(正面声量-负面声量)/(正面声量+负面声量)*100%。注意:这里的正面声量与负面声量使用的是实体情感算法得出的样本。实体情感介绍请参考”核心算法介绍–>(三)实体情感算法“。
2. 图表操作逻辑 #

①:tab键切换看不同平台的话题。
②:点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。
③:可点击升降序图标,表格将会按照这个字段的数字,降序或升序排列。
④:话题的名称,即平台中“#”后面的内容。点击这一行联动页面中其他图表展示跟这个话题有关的数据结果。
(三)趋势图 #
1. 统计逻辑 #
● 声量:品牌/车系(顶栏筛选器决定)在微博、短视频(抖音+微信视频号)两个阵地类型中每天的声量变化趋势。声量为有话题的帖子量。
● 互动量:品牌/车系(顶栏筛选器决定)在微博、短视频(抖音+微信视频号)两个阵地类型中每天的互动量变化趋势。互动量为有话题的帖子,互动指标的加总。不同平台的互动指标定义请参考”核心指标定义–>(二)互动量–>2. 互动量更新机制“。
● 默认显示:顶栏筛选条件下,涉及到的所有话题形成的声量趋势。
2. 图表操作逻辑 #

①:tab键切换看不同维度的趋势。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:鼠标随着X轴移动,将以悬浮框形式展示当天各个阵地的数据,以及总数。
④:任何一个图例都可以单独点击,比如单击微博,图例置灰,趋势图将不展示该阵地的数据;再一次单击微博,图例恢复颜色,趋势图将展示微博的数据。
(四)飙升热词 及 词云图 #
1. 统计逻辑 #
● 声量:品牌/车系(顶栏筛选器决定)在微博、短视频(抖音+微信视频号)两个阵地类型中每天的声量变化趋势。声量为有话题的帖子量。
● 互动量:品牌/车系(顶栏筛选器决定)在微博、短视频(抖音+微信视频号)两个阵地类型中每天的互动量变化趋势。互动量为有话题的帖子,互动指标的加总。不同平台的互动指标定义请参考”核心指标定义–>(二)互动量–>2. 互动量更新机制“。
● 默认显示:顶栏筛选条件下,涉及到的所有话题形成的声量趋势。
2. 图表操作逻辑 #
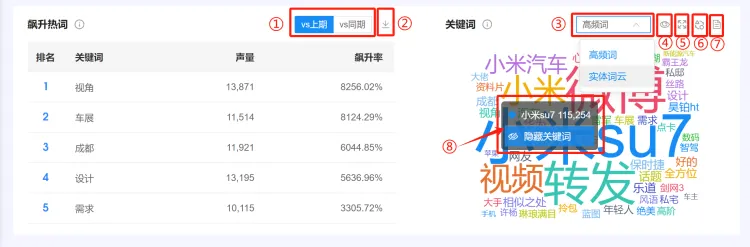
①:tab键切换看不同时间对比维度的数据。
②:点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。
③:通过下拉筛选器,查看不同类型的词云图。
④:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键 词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上⻆的“还原隐藏关键词”。
⑤:“放⼤”,点击后整个词云图将放⼤显示。
⑥:点击“设置词云图形状”,⻚⾯右侧弹出设置栏。选择并点击其中⼀个形状,如“汽⻋”,词云图将替 换成相应的样式。
⑦:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②⼀致。
⑧:⿏标放置到不同的关键词上,将以悬浮框形式展示这个关键词的声量。
(五)原文展示 #
具体功能请参考“系统图表介绍–>二、品牌剖析–>(十四)原文展示”。
六、微博人群画像、抖音人群画像、汽车之家人群画像 #
(一)信息来源 #
1. 微博 #
在微博上发表了与分析对象相关内容的用户,采集这些用户在平台上公开的个人身份信息,如下图。注意:受到用户填写信息的主动性、平台对用户信息的保护,页面展示的用户数量只占所有微博用户的一小部分。
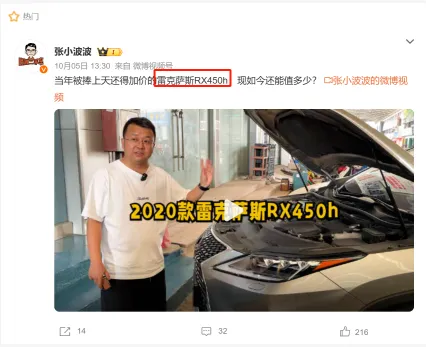

2. 抖音 #
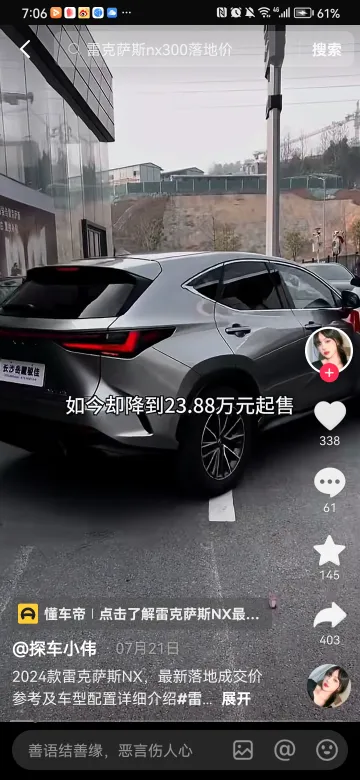
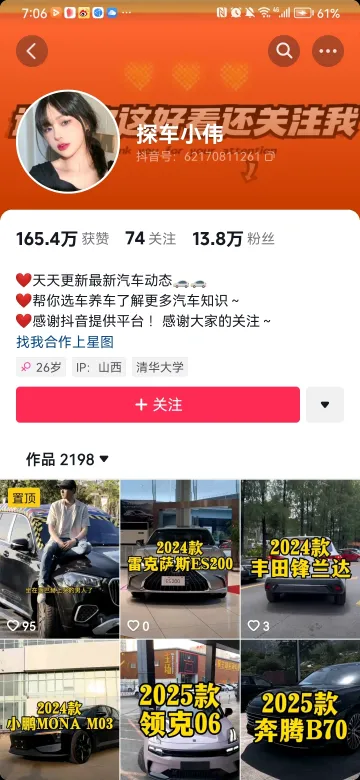
在抖音上发表了与分析对象先关的帖子的用户,基于这些用户在平台上公开的个人身份信息。如下图:
3. 汽车之家 #
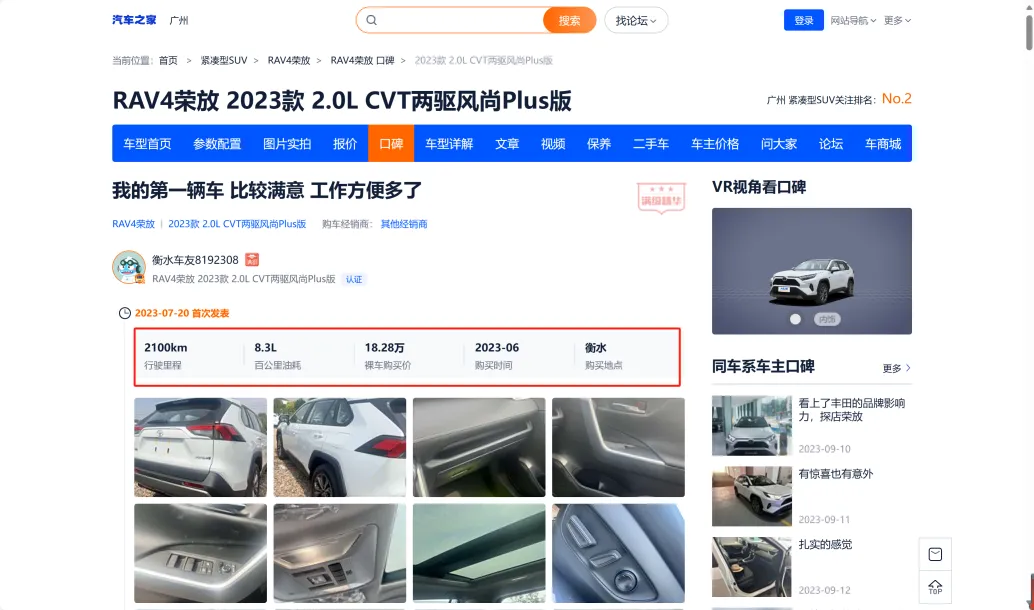
汽车之家,发表了口碑贴的用户,基于这些用户在平台上公开的个人身份信息。如下图:

(二)筛选器 #
1. 品牌/车系 #
● 单选。
● 技术品牌是指各品牌或厂商自主研发的核心技术,如丰田THS混动系统。
2. 细分市场 #
● A00-轿车:指微型车,轴距小于2450mm,车身长度在3900mm之内,发动机排量在1.0L左右。
● A0-轿车:指小型车,轴距在2350mm至2600mm之间,车身长度在3700mm至4450mm之间,发动机排量在1.0L至1.5L之间。
● A0-SUV:指小型SUV,其轴距小于2650mm,车身长度小于4450mm。
● A-轿车:指紧凑型轿车距为2500mm至2700mm之间,车身长度在4200mm至4600mm之间,发动机排量在1.6L至2.0L之间。
● A-SUV:指紧凑型SUV,轴距约在2500mm至2700mm之间,车身长度在4200mm至4600mm之间。
● A-MPV:指紧凑型MPV,轴距小于2850mm,车身长度小于4800mm。
● B-轿车:指中型车,轴距在2650mm至2950mm之间,车身长度在4600mm至5000mm之间,发动机排量在1.4L至3.0L之间。
● B-SUV:指中型SUV,轴距2700mm至2950mm之间,车身长度介于4550-4900mm之间。
● B-MPV:指中型MPV,轴距2850mm至3000mm,车身长度介于4750mm-4950mm之间。
● C-轿车:指中大型车,轴距约在2800mm至3150mm之间,车身长度在4800mm至5250mm之间,发动机排量超过2.0L。
● C-SUV:指中大型SUV,轴距2800至3150mm之间,车身长度介于4800mm-5200mm之间。
● C-MPV:指中大型MPV,轴距3000mm至3400mm,车身长度介于4900mm-5350mm之间。
● D-轿车:指大型车,其轴距超过2900mm,车身长度超过5100mm,发动机排量超过3.0L。
● D-SUV:指大型SUV,轴距大于2900mm,车身长度一般都大于5100mm。
● 跑车:跑车一般为双门设计,车身较低、造型流畅,有着比较强烈的运动感,座椅为双座或2+2式设计,与其他级别车型区别比较明显的是,跑车的发动机可以有前置、中置和后置三种形式;而且其车顶形式也有硬顶、硬顶敞篷和软顶敞篷三种。
● 微面:微型面包车的简称,是一种小型的客货两用型小汽车,一般有6~8个座位。
● 轻客:轻型客车,指不超过9座的客车。
● 微卡:微型卡车,是一种小型载货用汽车。其外形是在微面的基础上,车体后面加入封闭式货箱或货斗。车长小于等于3.5m,总质量小于等于1800kg。
● 轻卡:轻型卡车,N类载货车中最大设计总质量不大于4.5吨的N2类车型。
● 皮卡:皮卡是一种驾驶室后方设有无车顶货箱,货箱侧板与驾驶室连为一体的轻型载货汽车。它是前面像轿车,后面带货箱的客货两用汽车。
3. 数据筛选 #
● 情感类型:可筛选通过实体情感算法标识的帖子。
● 声量质量:可筛选不同质量类型的帖子。不同类型的定义请参考“五、核心算法介绍–(二)声量质量”。
● 内容包含及内容过滤:针对原文的“内容字段”,做关键词的搜索和过滤。关键词搜索时,可用以下表达方式进行组合:+代表"且",l代表"或",()代表"词组"。
● 能源分类:新能源包含“纯电动”“拆但是混合动力”“增程式”“燃料电池”;除此之外的为非新能源,比如汽油、油电混合等等。
4. 时间筛选 #
● 与”系统图表介绍–>一、品牌总览–>(一)筛选器–>3.时间筛选“保持一致。
(三)性别分布 及 年龄分布 #
1. 统计逻辑 #
● 用户数:在微博上(或者抖音、或者汽车之家)发表了和分析对象相关内容的用户数量(注意:受到用户填写信息的主动性、平台对用户信息的保护,页面展示的用户数量只占对应平台所有用户的一小部分)。
● 男性用户数:用户信息中,填写了男性的用户数量。
● 女性用户数:用户信息中,填写了女性的用户数量。
● 50后用户数:用户信息中,生日是1950年~1959年之间的用户数量。
● 60后用户数:用户信息中,生日是1960年~1969年之间的用户数量。
● 70后用户数:用户信息中,生日是1970年~1979年之间的用户数量。
● 80后用户数:用户信息中,生日是1980年~1989年之间的用户数量。
● 90后用户数:用户信息中,生日是1990年~1994年之间的用户数量。
● 95后用户数:用户信息中,生日是1995年~1999年之间的用户数量。
● 00后用户数:用户信息中,生日是2000年~2009年之间的用户数量。
● 10后用户数:用户信息中,生日是2010年~2019年之间的用户数量。
● 占比:男性占比=男性用户数÷用户数100%;女性占比计算同理。
● TGI:Target Group Index,目标群体指数。关注分析对象的微博用户中具有某一特征(比如男性)的用户数占比/微博总用户中具有相同特征(比如男性)的用户数占比100。反映目标群体在特定研究范围内的强势或弱势,其中TGI指数等于100表示平均水平;高于101,代表该类用户对分析对象的关注程度高于整体微博用户水平。
2. 图表操作功能 #
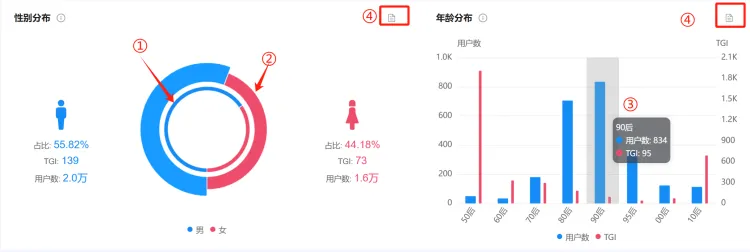
①:内圈为TGI。
②:外圈为用户数。
③:悬浮框
④:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(四)认证分布(微博人群画像) #
1. 统计逻辑 #
● 普通用户:在微博上发表了和分析对象相关内容,且没有获得黄V、橙V、金V认证,也不是微博达人的用户。
● 黄V、橙V、金V:微博个人认证等级,不同等级的认证条件如下图:

● 微博达人:微博达人是指在微博平台上活跃度高、影响力大、粉丝数量众多的用户。他们通常通过发布原创内容、分享有趣信息、参与热门话题讨论等方式,吸引大量粉丝关注,并在微博上形成一定的舆论影响力。申请达人需要满足以下条件:拥有头像,绑定手机,关注数达到100,有效互粉数至少30,以及微博等级达到LV3。
● 普通用户占比=普通用户数÷(普通用户数+黄V用户数+微博达人用户数+橙V用户数+金V用户数)*100%
2. 图表操作功能 #

①:鼠标在环形图上移动,将以悬浮框显示这种认证类型的用户有多少人。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
③:任何一个图例都可以单独点击,比如单击普通用户后,图例置灰,环形图将不展示该类型的数据;再一次单击普通用户后,图例恢复颜色,环形图将展示类型的数据。
④:全选是指全部图例对应的类型都选上,环形图中呈现所有类型的数据;反选则可以一次过将所有图例置灰。
(五)地区分布 及 城市级别分布 #
1. 统计逻辑 #
● 用户填写的个人信息中,对应的地区。
● TGI:Target Group Index,目标群体指数。关注分析对象的微博用户中具有某一特征(比如一线城市)的用户数占比/微博总用户中具有相同特征(比如一线城市)的用户数占比*100。反映目标群体在特定研究范围内的强势或弱势,其中TGI指数等于100表示平均水平;高于101,代表该类用户对分析对象的关注程度高于整体微博用户水平。
● 城市级别划分采用微博开放平台提供的省份城市编码表。
2. 图表操作功能 #
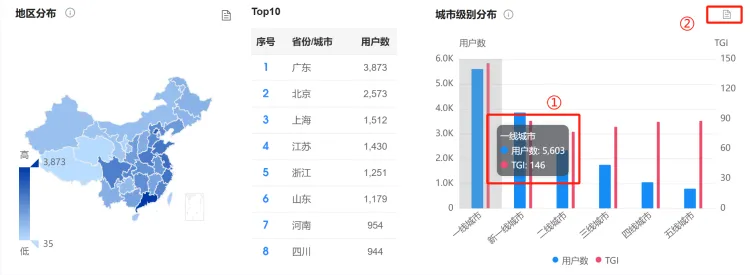
①:鼠标在柱状图上移动,将以悬浮框显示该级别的城市总共有多少用户以及对应的TGI。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(六)常用客户端(微博人群画像) #
1. 统计逻辑 #
● 数据来自于每条微博主贴自带的客户端,也就是用户用什么客户端发的微博,如下图:
● 悬浮框中的数字代表有230条微博主贴是用三星android智能手机客户端发表的。注意:系统仅针对带了终端信息的微博主贴进行统计。

2. 图表操作功能 #

①:鼠标放置到不同的关键词上,将以悬浮框形式展示这种类型的数据。
②:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上角的“还原隐藏关键词”。
③:“放大”,点击后整个词云图将放大显示。
④:点击“设置词云图形状”,页面右侧弹出设置栏。选择并点击其中一个形状,如“汽车”,词云图将替换成相应的样式。
⑤:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(七)活跃时间(小时)(微博人群画像) #
1. 统计逻辑 #
● 统计每条微博主贴,用户发帖的时刻,如下图。计算每个时刻里,有多少用户发表和分析对象相关的微博。
2. 图表操作功能 #

①:鼠标放置到不同的柱子上,将以悬浮框形式展示这个时间,有多少人发表了微博。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(八)粉丝数量分布(微博人群画像) #
1. 统计逻辑 #
● 数据来自于发帖用户的粉丝量数据。如下图。统计不同粉丝数量区间的人数分布。

● TGI:Target Group Index,目标群体指数。关注分析对象的微博用户中具有某一特征(比如1W及以上)的用户数占比/微博总用户中具有相同特征(比如1W及以上)的用户数占比*100。反映目标群体在特定研究范围内的强势或弱势,其中TGI指数等于100表示平均水平;高于101,代表该类用户对分析对象的关注程度高于整体微博用户水平。
2. 图表操作功能 #
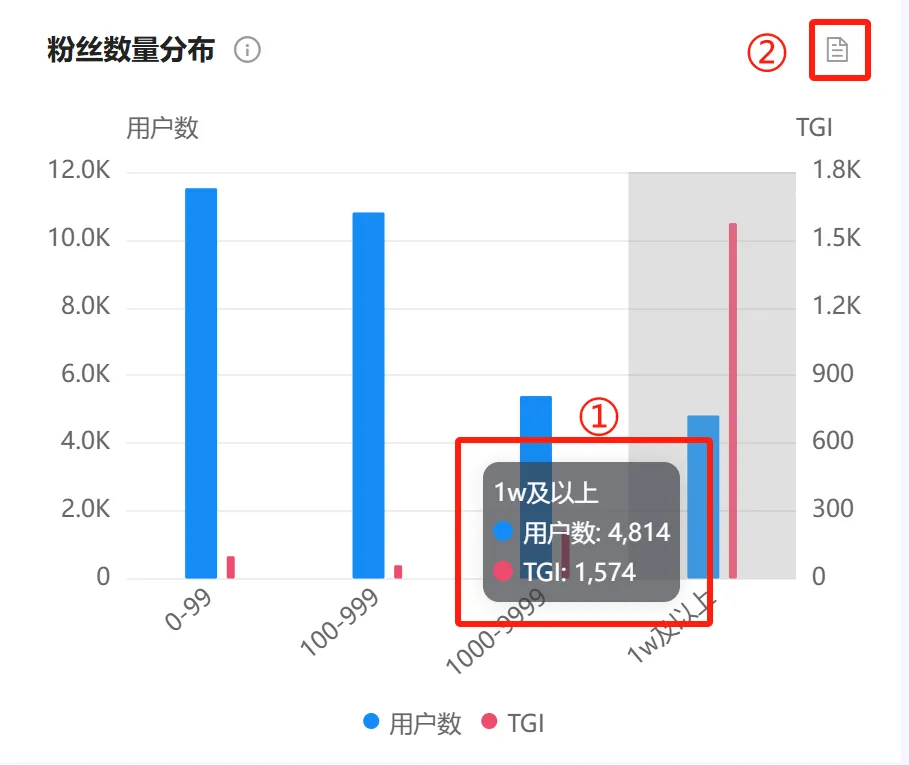
①:鼠标在柱状图上移动,将以悬浮框显示该粉丝量级的用户总共有多少个,以及对应的TGI。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(九)用户感兴趣内容(微博人群画像、抖音人群画像) #
1. 统计逻辑 #
● 通过结合用户本身的标签及其关注用户的标签进行权重计算,排序取权重前100的标签作为用户感兴趣内容的标签。
2. 图表操作功能 #

①:鼠标放置到不同的关键词上,将以悬浮框形式展示这种内容的帖子量。
②:“隐藏关键词”和“还原隐藏关键词”:当有看到不符合预期的关键词时,可点击浮框中”隐藏关键词“,将其隐藏不显示;若想取消隐藏,将这个词还原出来,可以点击右上角的“还原隐藏关键词”。
③:“放大”,点击后整个词云图将放大显示。
④:点击“设置词云图形状”,页面右侧弹出设置栏。选择并点击其中一个形状,如“汽车”,词云图将替换成相应的样式。
⑤:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(十)关注用户排名(微博人群画像、抖音人群画像) #
1. 统计逻辑 #
● 关注用户是指,在微博、抖音上发表和分析对象相关内容的用户,他们关注了哪些用户?(注:因为受到平台反爬的制约(保护用户的隐私),因此系统没法将所有用户完整的关注列表都采集到,建议此数据结果只作参考)业务方可参考该名单,找到目标用户关注的KOL,对营销策略提供参考方向。
2. 图表操作功能 #

● 点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。
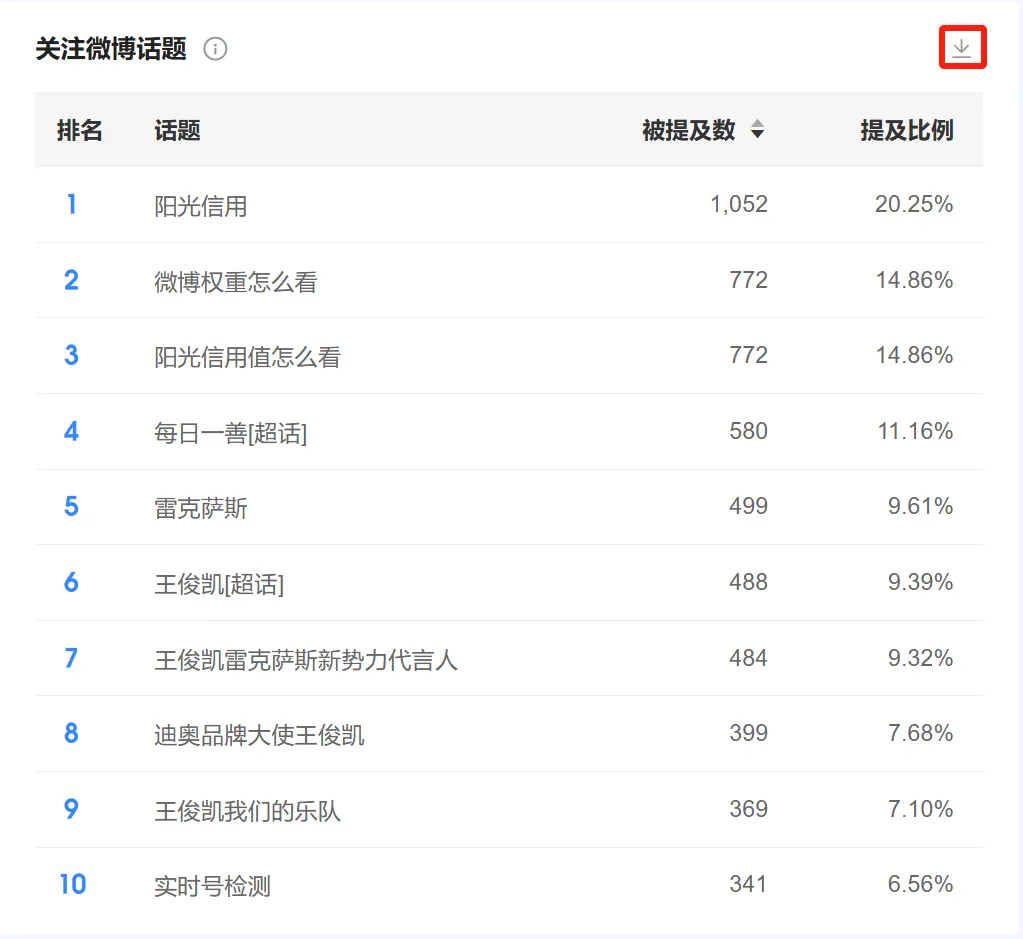
(十一)关注微博话题 及 关注抖音话题 #
1. 统计逻辑 #
● 图表结果显示提及到所选品牌/车系内容的这批用户,在发表微博内容,或者抖音视频时会提及哪些话题(带#的内容)。如下图:

2. 图表操作功能 #
● 点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。
(十二)话题原文(微博人群画像) #
1. 统计逻辑 #
● 在微博上带上话题的原贴。
2. 图表操作功能 #
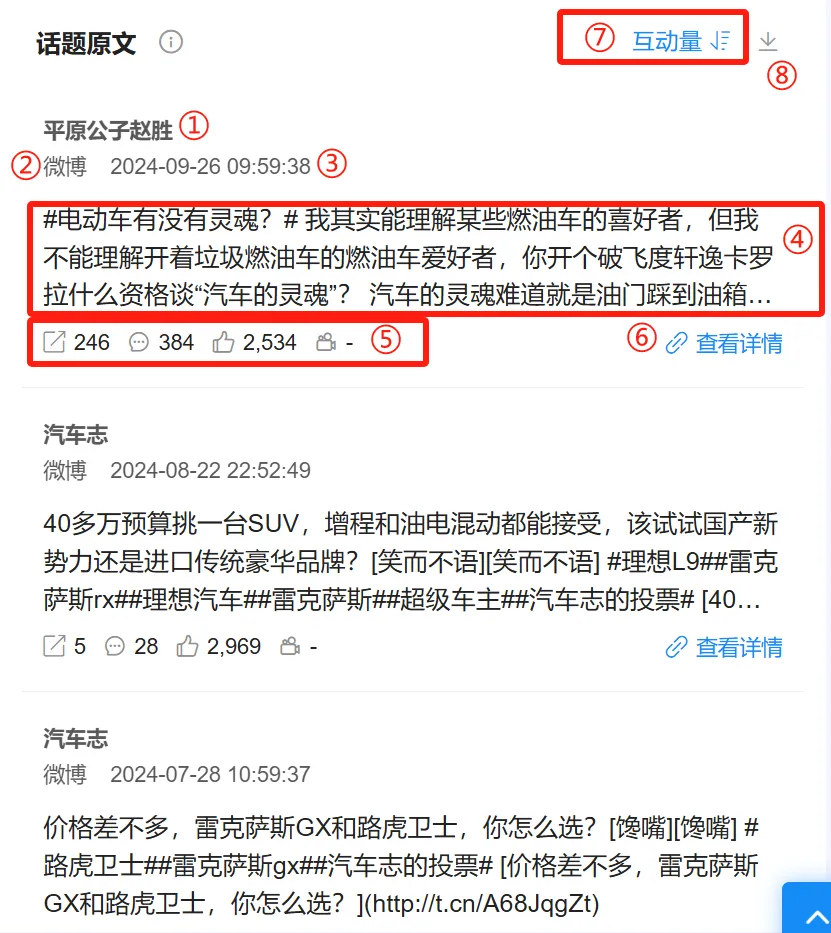
①:发布这条帖子的账号名称。
②:发布这条帖子的站点。
③:发布这条帖子的时间。
④:这条帖子的内容。
⑤:这条帖子的互动量指标。
⑥:点击“查看详情”可打开这条帖子对应的网页链接。
⑦:原文展示过程中,可以根据互动量大小,升降序排列;也可以按照评论数,或者按照时间进行排序展示。
⑧:点击右上角下载按钮,可通过CSV文件导出头200条原文。、
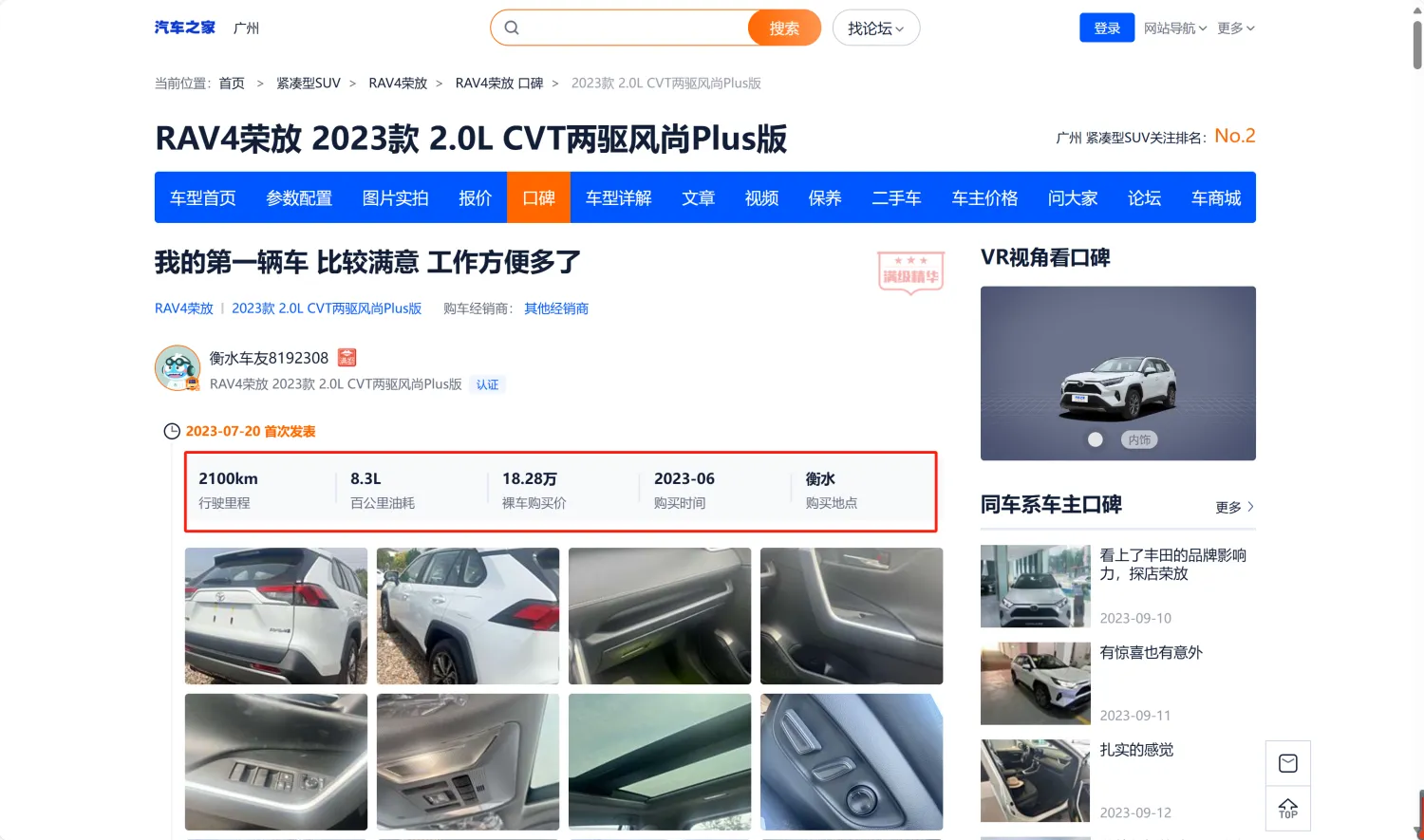
(十三)裸车购买价格分布(汽车之家人群画像) #
1. 统计逻辑 #
● 统计购买不同裸车价区间的用户数。数据来资源汽车之家口碑帖中,用户填写的“裸车购买价”,如下图:
2. 图表操作功能 #
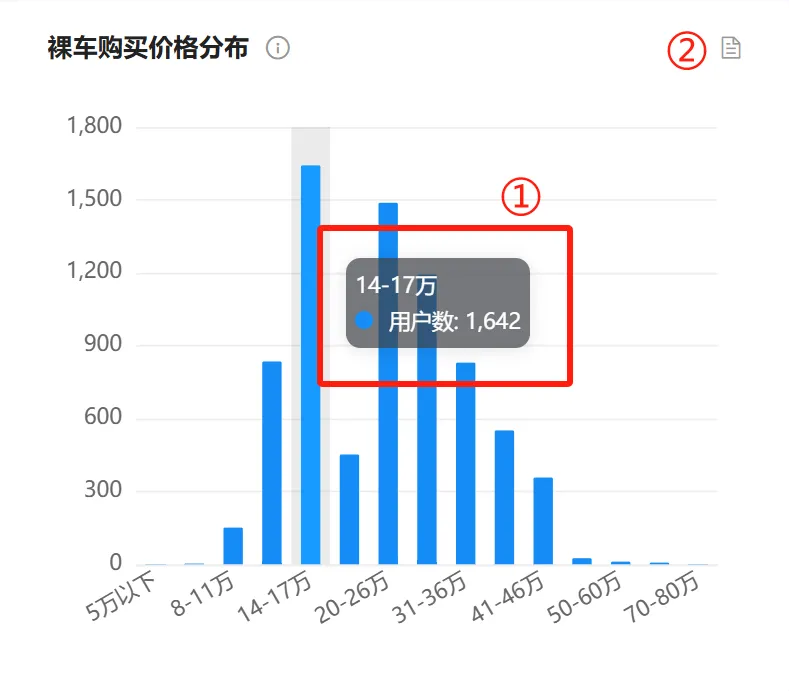
①:鼠标在柱状图上移动,将以悬浮框显示该裸车价区间的用户总共有多少个。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
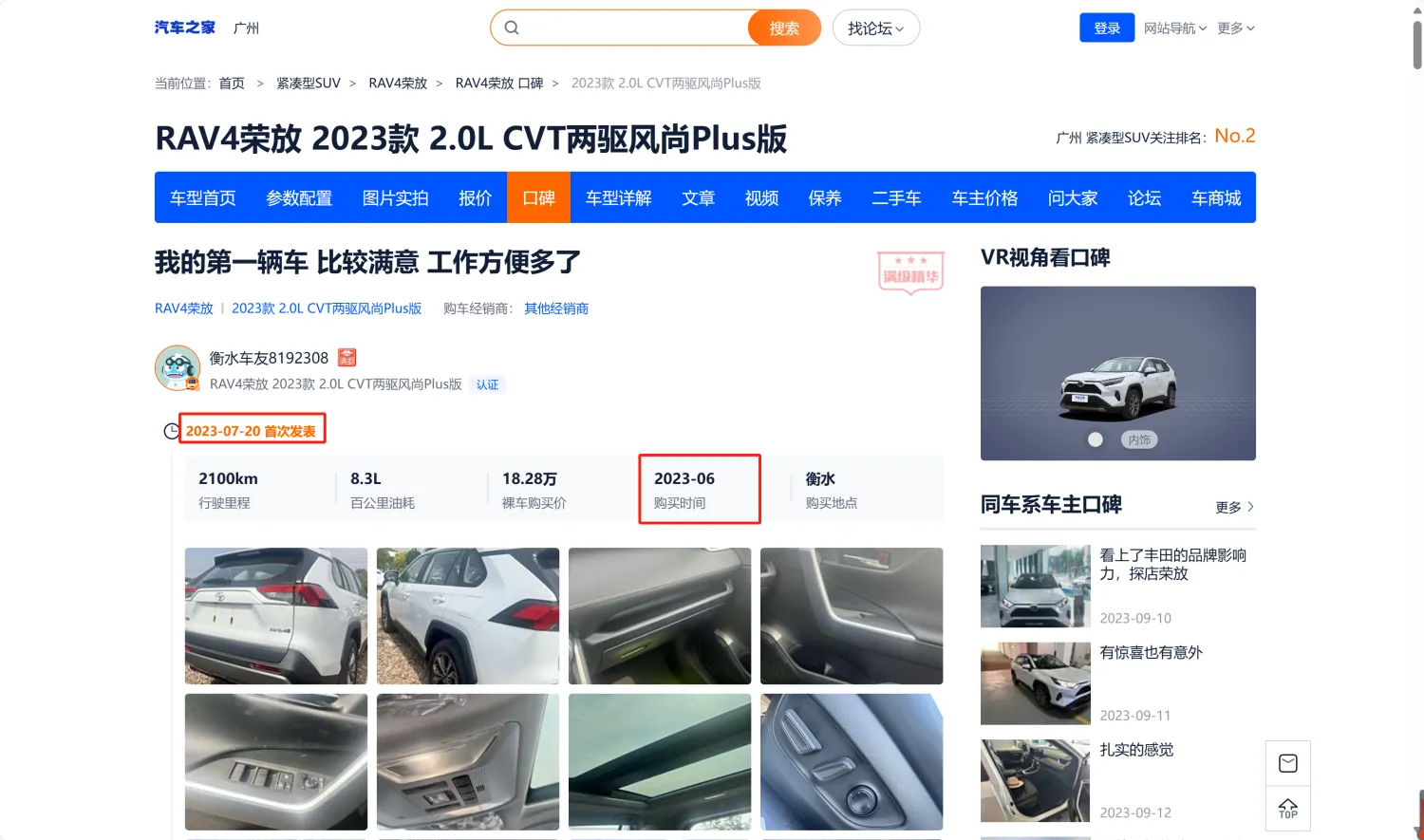
(十四)购车时间与发表时间间隔分布(汽车之家人群画像) #
1. 统计逻辑 #
● 采集汽车之家口碑贴中,用户填写的购买时间,以及发表时间;计算两个时间的差距,并统计不同区间内的用户数。如下图:
2. 图表操作功能 #
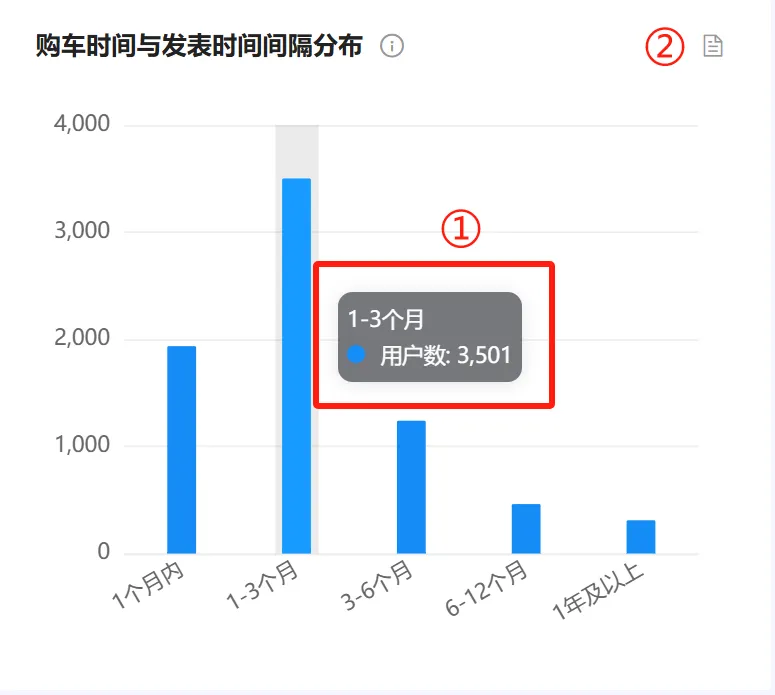
①:鼠标在柱状图上移动,将以悬浮框显示该区间的用户总共有多少个。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
(十五)行驶里程分布(单位:公里)(汽车之家人群画像) #
1. 统计逻辑 #
● 采集汽车之家口碑贴中,用户填写的行驶里程分布;统计不同区间内的用户数。如下图:

2. 图表操作功能 #

①:鼠标在柱状图上移动,将以悬浮框显示该区间的用户总共有多少个。
②:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
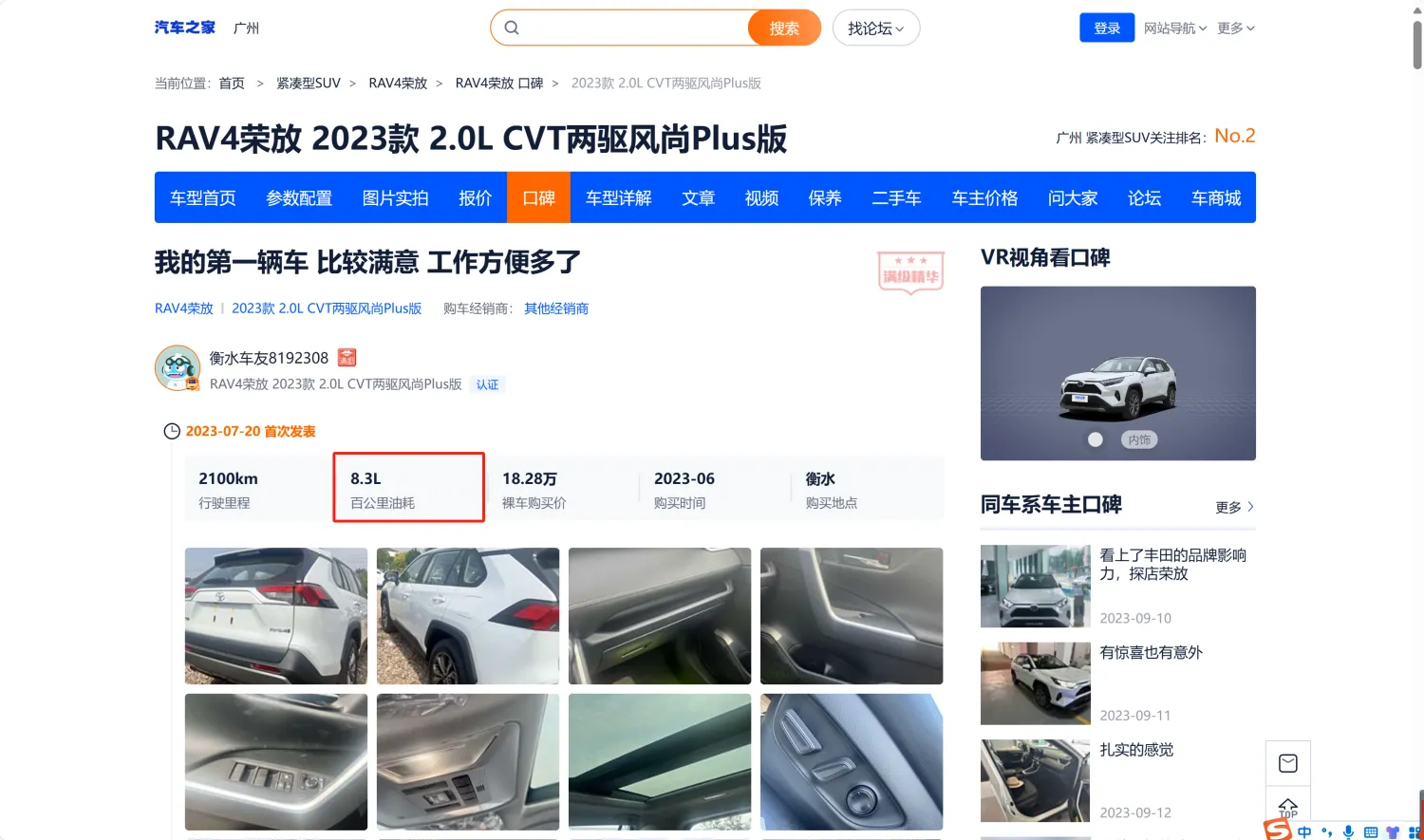
(十六)油耗/电耗分布(单位:百公里)(汽车之家人群画像) #
1. 统计逻辑 #
● 采集汽车之家口碑贴中,用户填写的百公里油耗,或者春秋电耗;统计不同区间内的用户数。如下图:

2. 图表操作功能 #

:鼠标在柱状图上移动,将以悬浮框显示该区间的用户总共有多少个。
②:tab键切换看不同类型的能源分布。
③:表格视图,功能与【品牌总览】-声量分布,图表操作功能中的②一致。
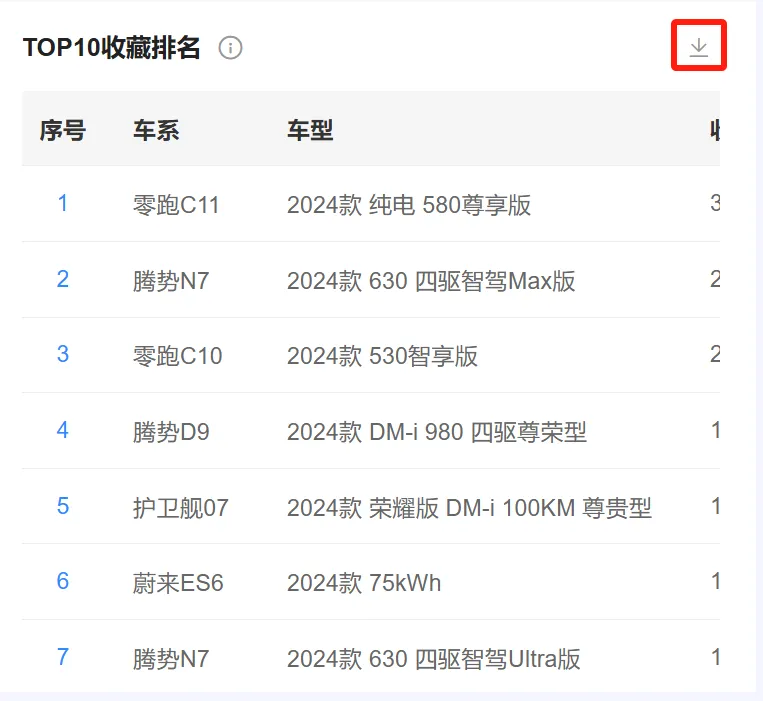
(十七)TOP10收藏排名(汽车之家人群画像) #
1. 统计逻辑 #
● 采集汽车之家口碑贴对应的用户信息中,自己收藏的车型,统计不同车型被收藏的用户数。如下图:
2. 图表操作功能 #
● 点击右上角下载按钮,可导出CSV文件,字段包含系统页面上看到的这些内容。