一、产品简介 #
品牌监测可以帮助业务侧直观量化各大品牌在社媒上的营销表现,并支持对品牌进行多维度地剖析,进而对营销表现进行归因,助力企业优化营销策略,达到降本增效的目的。
|
模块
|
功能
|
|---|---|
|
模块
|
功能
|
| 品牌总览 | 总览各品牌整体趋势变化,快速判断是否存在某个品牌的崛起 |
| 品牌剖析 | 深度剖析品牌表现及传播力 |
| 品牌对标 | 追踪对比本竞品传播表现情况 |
| 热门话题 | 了解关注的品牌在社媒上被热议的话题 |
| 微博人群画像 | 多维度地分析某品牌微博阵地的目标用户 |
| 抖音人群画像 | 多维度地分析某品牌抖音阵地的目标用户 |
二、重要概念说明 #
声量质量
通过社媒营销广告算法将所有的社媒声量分为内容营销广告、自发创作、追星文、新闻公关、促销团购、其它,详细定义参见指标维度说明。
声量类型
将所有的社媒声量分类PGC/BGC/UGC/明星三个类型,详细定义参见指标维度说明。
人群
用户发帖中提及品牌相关关键词则定义为品牌人群
三、数据说明 #
1.数据来源 #
| 阵地 | 细分站点说明 |
|---|---|
| 微博 | 新浪微博 |
| 微信 | 微信公众号文章 |
| 新闻 | 覆盖今日头条、一点资讯、ZAKER新闻、百度新闻、新浪新闻、百度搜索、搜狗搜索、中国新闻网、中国财经信息网、凤凰网_财经、东方网等主流站点的新闻频道 |
| 论坛 | 覆盖中国网管论坛、电子发烧友论坛、百度贴吧、豆瓣、虎扑、大众点评、中关村_在线论坛、天涯论坛等各行业的主流论坛站点 |
| 电商笔记 | 小红书、得物app笔记 |
| 短视频 | 抖音app、快手app |
| 视频 | 哔哩哔哩、腾讯视频、优酷、爱奇艺、AcFun、PPTV聚力、芒果TV、乐视 |
| 问答 | 覆盖知乎、百度知道等主流问答站点 |
2.指标说明 #
|
指标 |
含义 |
|
声量 |
分析对象被提及的文本数量,若在同一条文本被提及多次,声量记1 |
|
互动量 |
针对分析对象被提及文本的所有互动指标之和,包括转发数/评论数/点赞数/收藏数等,阅读数、观看数及播放数等为浅层互动或曝光,不纳入标准互动量计算范围。 |
| 平均互动量 | 平均互动量=本期的互动量/ 本期的声量 |
|
SOV(Share of Voice,声量份额) |
当前品牌声量/所评估品牌总声量*100% |
|
SOE(Share Of Engagement,互动量份额) |
当前品牌互动量/所评估品牌总互动量*100% |
|
PSR(Positive Sentiment Rate,好评度) |
PSR=正面情感值/(正面情感值+负面情感值)*100%。 通过计算品牌在网上正面与负面评价比例来分析品牌在网上口碑。 |
|
NSR(Net Sentiment Rate,净情感度) |
NSR=(正面情感值-负面情感值)/(正面情感值+负面情感值)*100%。 跟好评度一样都反映了消费者对某品牌的好感度。不同点在于,其在好评度的基础上进一步体现了负面评论的影响 |
| 正面率 | 正面率=正面情感值/(正面情感值+中性情感值+负面情感值)*100% |
| 负面率 | 负面率=负面情感值/(正面情感值+中性情感值+负面情感值)*100% |
|
同比相关指标 |
同比=(本期指标值-去年同期指标值)/去年同期指标值 * 100% 比如:声量同比=(本期声量值-去年同期声量值)/去年同期声量值* 100% |
|
环比相关指标 |
环比=(本期指标值-上期指标值)/上期指标值* 100% 比如:声量环比=(本期声量值-上期声量值)/上期声量值* 100% |
|
TGI(Target Group Index,目标群体指数) |
[关注品牌的用户中具有某一特征的群体所占比例/总用户中具有相同特征的群体所占比例]*标准数100。反映目标群体在特定研究范围内的强势或弱势,其中TGI指数等于100表示平均水平,高于100,代表该类用户对某类问题的关注程度高于整体水平。 |
3.维度说明 #
|
维度 |
定义 |
|
阵地 |
同一类数据源的总称,例如:新浪新闻、搜狐新闻、腾讯新闻等均属于“新闻阵地”。 |
|
声量质量 |
1.内容营销广告: 内容以营销为目的、通过多方面正面评价和推广品牌/产品来吸引消费者购买,一般由品牌方、合作明星及KOL发布。 数据示例:
2.自发创作: 消费者客观描述品牌感知、产品体验、分享知识点等,用词表达口语化较多。 数据示例:
3.追星文: 由粉丝发起,为提升明星知名度或表达对明星喜爱。可借助追星文的声量比例评估代言人的社媒影响力。 数据示例:
4.新闻公关: 内容多与企业的公益慈善、经营管理、形象危机相关,目的在于品牌形象管理,常见的形式包括新闻通稿、公关文等。 数据示例:
5.促销团购: 文本内容虽然提及品牌/产品,但是内容并不能提高品牌/产品的影响力。常见的数据特征有团购信息、返利平台推广信息、优惠券发放等。 数据示例:
6.其它: 算法暂时无法进行归类识别的文本数据。 |
|
声量类型 |
通过作者的粉丝数和认证类型,将声量分成了BGC、PGC、UGC、明星四类。不同阵地有不同的条件,具体见下方介绍。
|
|
微博-性别 |
根据微博用户填写的性别信息进行统计 |
|
微博-年龄分布 |
根据用户填写的出生年份信息进行分段统计。 50后及以上:<1960; 60后:1960=<出生年份<1970; 70后:1970=<出生年份<1980; 80后:1980=<出生年份<1990; 90后:1990=<出生年份<1995; 95后:1995=<出生年份<2000; 00后:2000=<出生年份<2010; 10后及以下:2010=<出生年份; |
|
微博-认证分布 |
根据用户所属的认证类型进行统计,统计普通用户,黄V,金V,普通达人,蓝V |
|
微博-地区分布 |
根据用户填写的所在省份/城市信息进行统计 |
|
微博-城市级别 |
一线城市: 北京,上海,广州,深圳 二线城市: 保定,金华,兰州,廊坊,绍兴,台州,中山,珠海,泉州,哈尔滨,贵阳,烟台,太原,昆明,南通,济南,常州,徐州,南宁,南昌,长春,嘉兴,无锡,石家庄,温州,惠州,宁波,福州,厦门,大连 三线城市: 洛阳,潍坊,扬州,安庆,蚌埠,滁州,阜阳,黄冈,荆州,九江,六安,马鞍山,南充,宁德,莆田,清远,商丘,上饶,新乡,信阳,宿迁,肇庆,驻马店,遵义,潮州,菏泽,宿州,宜春,周口,绵阳,鞍山,赣州,江门,襄樊,连云港,呼和浩特,临沂,邢台,衡阳,江阴,张家港,湛江,济宁,镇江,邯郸,沧州,芜湖,株洲,银川,乌鲁木齐,漳州,威海,盐城,揭阳,海口,宜昌,柳州,汕头,大庆,南阳,唐山,淮安,桂林,秦皇岛,淄博,咸阳,舟山,岳阳,义乌,三亚,泰州,襄阳,泰安,湖州,昆山 四线城市: 包头,宝鸡,滨州,常德,郴州,德阳,东营,鄂尔多斯,吉林,聊城,龙岩,梅州,齐齐哈尔,西宁,榆林,运城,渭南,延安,安阳,锦州,四平,大同,邵阳,牡丹江,葫芦岛,晋中,曲靖,玉溪,通辽,盘锦,十堰,攀枝花,内江,日照,益阳,平顶山,本溪,绥化,开封,辽阳,朝阳,资阳,孝感,通化,三明,韶关,德州,延边,吉安,娄底,淮南,枣庄,吕梁,赤峰,南平,黄山,许昌,永州,衢州,抚顺,阳江,茂名,丹东,丽水,焦作,湘潭,承德,铁岭,拉萨,泸州,荆门,延边朝鲜族自治州,张家口,巢湖,临汾,宜宾,营口,黄石,乐山,衡水,达州 五线城市: 大兴安岭,海安,天门,潜江,广元,吴忠,陇南,仙桃,文山,博尔,白银,黑河,铜川,诸暨,巴音郭楞,巴中,莱西,博尔塔拉蒙古自治州,临沧,克孜勒苏,乌海,果洛,福清,佳木斯,随州,吐鲁番,兴安盟,兴化,邳州,章丘,崇明,三河,安顺,毕节,寿光,长兴县,果洛藏族自治州,白山,巴彦淖尔盟,长安镇,鳌江-龙港镇,德宏傣族景颇族自治州,奉化,固原,诸城,如皋,文山壮族苗族自治州,宣城,那曲,湘西土家族苗族自治州,和田,大洼县,海东,辽源,浏阳,甘南,余姚,保山,恩施,闽侯县,孝义,阿勒泰,鹤壁,石嘴山,楚雄,广安,高密,德清县,晋江,库尔勒,河池,阜新,胶南,克孜勒苏柯尔克孜自治州,梧州,新沂,招远,黔西南,贵港,西双版纳,玉树,桓台县,荣成,邹平县,临夏回族自治州,甘孜,抚州,恩施土家族苗族自治州,阿坝,黔东南,虎门镇,汕尾,兖州,河源,玉林,阿克苏,嘉善县,林芝,新郑,黄南,建湖县,黔东南苗族侗族自治州,神木县,白城,黔南布衣族苗族自治州,阳泉,儋州,迪庆藏族自治州,海西蒙古族藏族自治州,酒泉,玉环,萍乡,鄂州,甘孜藏族自治州,海北藏族自治州,玉树藏族自治州,海门,新泰,如东县,准格尔旗,凉山,昌吉回族自治州,肥西县,西昌,红河,怀化,红河哈尼族彝族自治州,咸宁,张家界,天水,崇左,商洛,迁安,锡林郭勒盟,武威,肥城,哈密,黄南藏族自治州,阿坝藏族羌族自治州,新密,伊金霍洛旗,昭通,铜陵,池州,海南藏族自治州,防城港,钦州,莱州,六盘水,湘西,鹰潭,嘉峪关,调兵山,靖江,庆阳,汉中,三沙,三门峡,开原,石河子,赣榆县,丰县,蓬莱,博罗县,莱芜,朔州,海宁,新余,伊犁,呼伦贝尔,云浮,东台,伊宁,临海,仪征,德宏,沭阳县,即墨,金坛,遂宁,金昌,惠安县,山南,永康,长治,青州,阿里,西双版纳傣族自治州,龙海,平度,平湖,大理,松原,伊犁哈萨克自治州,宁海县,东阳,海城,黔南,普洱,楚雄彝族自治州,邹城,乌兰察布盟,永安,自贡,龙口,贺州,甘南藏族自治州,泰兴,伊春,平凉,鸡西,丽江,铜仁,克拉玛依,濮阳,临夏,亳州,百色,雅安,晋城,忻州,济源,塔城,文登,来宾,庄河,常熟,巩义,思茅,中卫,武安,迪庆,双鸭山,辽中县,漯河,昌都,眉山,新民,昌吉,海南,宁乡县,东港,鹤岗,淮北,黔西南布衣族苗族自治州,大丰,安康,海西,启东,增城,阿拉善盟,沛县,怒江,七台河,日喀则,定西,景德镇,丹阳,张掖,北海,胶州,海北,凉山彝族自治州,府谷县,怒江傈僳族自治州,喀什,郫县 新一线: 成都,东莞,佛山,杭州,合肥,南京,青岛,沈阳,苏州,天津,武汉,西安,长沙,郑州,重庆 |
|
微博-活跃时间 |
按发帖的小时数进行聚合统计,如12点05分发贴即计入12那个时刻的数据 |
|
微博-爱好标签 |
根据用户及其关注的用户的近期发文,判断出每个用户最突出的80个爱好标签,并基于此信息进行统计。 |










四、操作说明 #
1.品牌总览 #
可快速了解本竞品的核心指标如声量、互动量、PSR等在各个阵地的社媒本期表现与变化
【品牌总览】
概览本竞品的社媒表现情况
【操作】支持自定义显示字段和数据下载

【声量/互动量分布】
查看各大品牌在不同阵地的声量(互动量)分布,可通过柱状图高低快速判断品牌的社媒总声量(总互动量)大小和不同阵地的声量高低,进而定位本竞品社媒表现强势与弱势的阵地

查看各个阵地上不同品牌的声量(互动量)分布,可通过柱状图高低快速判断用户活跃度高的阵地、比较在各个阵地本竞品的讨论热度并定位在各个阵地表现强势的品牌

【各品牌下不同阵地平均互动量分布】
借助热力图,从阵地与品牌两个维度,了解用户的互动意愿高低,并快速定位到互动意愿最高的阵地与品牌
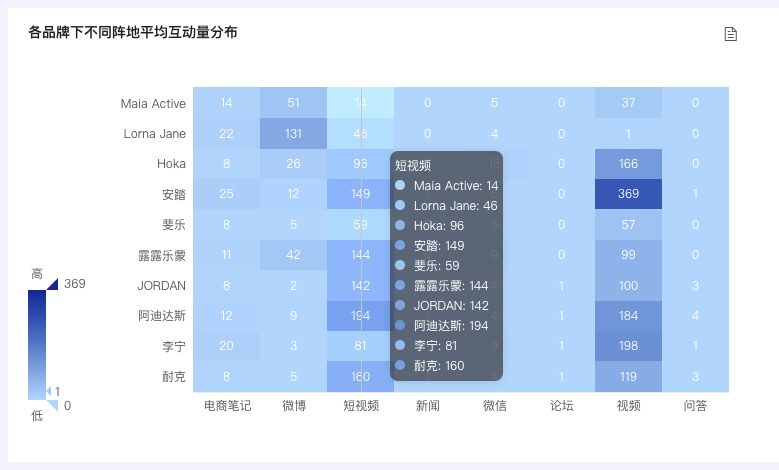
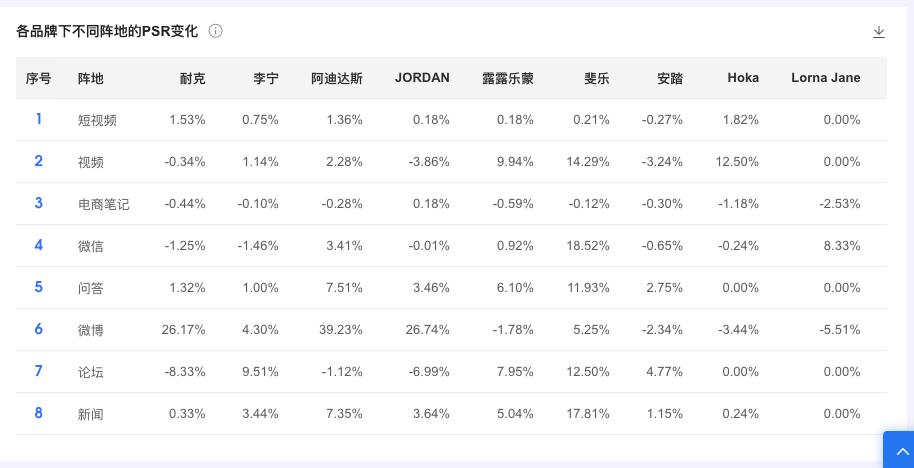
【各品牌下不同阵地PSR表现(%)】
借助热力图,从阵地与品牌两个维度,迅速了解PSR的分布

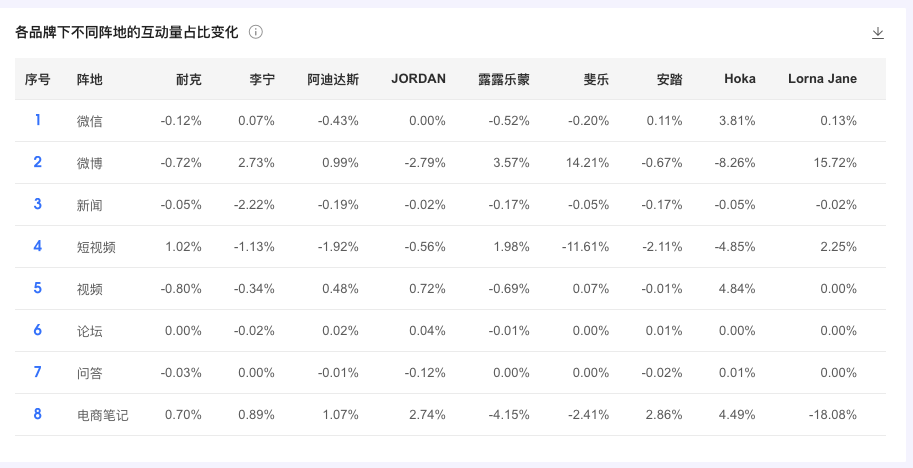
【各品牌下不同阵地的声量(互动量、平均互动量、PSR)占比变化】
快速浏览在各个阵地各大品牌的声量(互动量)的变化,可与声量(互动量、平均互动量、PSR)分布搭配使用


2.品牌剖析 #
深度分析感兴趣的品牌,剖析品牌社媒表现,进而对营销策略进行归因分析
【品牌/系列筛选器】
查看想要深度剖析的品牌/系列,每次只可选一个

【组合筛选器】
可对情感类型、数据阵地、声量类型、声量质量进行筛选,用户也可通过内容包含和内容过滤,筛选出或过滤掉想分析的特定内容

【时间筛选器】
可选择特定时间范围来查看数据。支持按月/按日筛选时间。


【指标卡】
可知悉社媒上关注品牌本期的声量、互动量、PSR的社媒表现与变化

【声量/互动量各阵地占比及趋势】
展示品牌在各个阵地的声量、互动量趋势

- 以图例区分阵地,以便了解整体趋势变化和分阵地趋势变化。
- 如需查看特定阵地的趋势,可使用顶部的组合筛选器,或点击图例。其中,组合筛选器会影响联动本页面的所有图表,点击图例仅影响趋势图。
- 支持联动其他图表。点击某一天的数据点,可以查看这一天的 指标卡、声量占比、互动量占比、阵地分布、声量类型占比、情感占比、topic分布、词云图、Top10事件列表、粉丝量级分布及其互动量Top30作者、原帖。
- 如需查看趋势图的具体数据,可点击右上角的
 按钮切换到表格视图,在表格视图中亦支持下载数据表。
按钮切换到表格视图,在表格视图中亦支持下载数据表。
【各阵地分布】
展示品牌在各个阵地的核心指标,支持按声量、互动量、平均互动量查看

【声量类型占比分布】
展示不同发声类型的占比

- 以图例区分声量类型,以便了解不同声量类型的占比
【情感占比分布】
利用情感算法判断数据内容的情感倾向,展示不同情感的占比

- 以图例区分情感类型,以便了解不同情感的占比
【品牌/产品Topic】
针对不同品牌/产品系列的声量进行内容分析,聚类为鞋服行业关注品牌、产品共2个一级topic,并针对2个一级topic分别细分二级topic
品牌:产品/品类、品牌活动、赛事活动、体育明星、娱乐明星
产品:购买攻略、出售转让、服务/售后、新品、产品分享、山寨假货、开箱、促销团购、穿搭、联名、测评、平台引流帖
| 一级topic | 二级topic |
定义 |
|---|---|---|
| 品牌 | 产品/品类 | 品牌下提及产品/品类的帖子 |
| 品牌活动 | 由品牌方发起的,与品牌营销相关的品牌活动 | |
| 赛事活动 | 运动领域中的运动赛事,如奥运会、篮球联赛等 | |
| 体育明星 | 品牌与体育明星共同提及 | |
| 娱乐明星 | 品牌与娱乐明星共同提及 | |
| 产品 | 山寨莆田 | 高仿/莆田类讨论的帖子 |
| 平台引流帖 | 以搞笑/游戏/情感为主要内容的短剧,其中穿插识货或得物的平台引流内容 | |
| 产品分享 | 提及产品和【分享|推荐|晒单|好物|挖到宝】等 | |
| 穿搭 | 提及产品或者品类穿搭/搭配相关的帖子,基本带有【穿搭|ootd】的关键词 | |
| 开箱 | 提及产品开箱相关的帖子,基本带有【开箱】的关键词 | |
| 测评 | 针对特定产品的使用测评 | |
| 联名 | 品牌提及产品联名/品牌联名的帖子 | |
| 新品 | 提及新品发售/上市内容的帖子 | |
| 促销团购 | 以商品促销内容为主的,发起的对象不限于品牌方/平台方 | |
| 服务售后 | 提及与消费者的售后体验/购买体验,或商家所提供的售后服务类型等内容的帖子 | |
| 出售转让 | 提及二手商品的促销内容 | |
| 购买攻略 | 提及省钱攻略、低价攻略、促销清单、凑单攻略、年度榜单、购物清单等相关内容 |

【词云图】
支持切换查看topic词云、高频词云、话题词云。按声量降序展示top80个

- topic词云:通过算法提取不同的topic,并统计topic词对应的声量,展示热门topic词
- 高频词云:通过关键词识别算法提取帖子的关键词,并统计关键词对应的声量,展示热门关键词
- 话题词云。通过提取平台话题标签,并统计话题标签对应的声量,展示热门话题词
【Top10事件列表】
对所有帖子进行聚类,展示热度Top10事件。默认按互动量降序

【粉丝量级分布】
分析品牌/系列声量不同粉丝数量级别的用户数、声量、互动量的分布情况。这里只分析声量类型为PGC和UGC的发帖;
其中粉丝数量级别分为超头部、头部、上腰部、下腰部、尾部、KOC;且覆盖的站点为微博、微信、抖音、快手、小红书、哔哩哔哩。

- 可点击某一粉丝量级与互动量Top30作者、原帖联动,查看该粉丝量级下的Top30作者信息与帖子内容
- 可点击取消联动,去除联动效应
【互动量Top30作者】
统计品牌/系列声量各粉丝量级所获互动量最大的前三十个作者
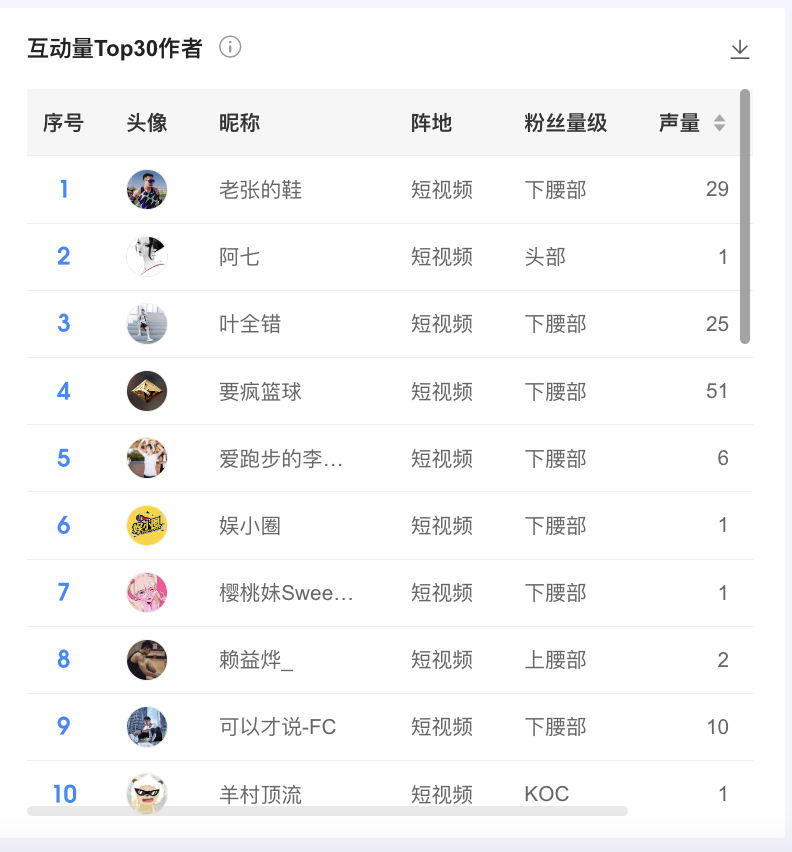
- 可点击某一作者与原帖联动,查看该作者的帖子内容
- 可点击取消联动,去除联动效应
3.热门话题 #
可了解与品牌相关的热门话题

筛选器:使用方式可参考 品牌剖析页
话题列表:了解在哪些热门话题下,消费者会提起这些品牌,以及对品牌的情感指向
- 支持微博平台、小红书平台、抖音平台自带话题
- 支持通过算法对全阵地的内容进行聚类,查看热门事件
- 可点击话题与本页面其余所有板块联动,查看该话题的热度趋势、热词、帖子内容
趋势图:可查看话题的热度趋势
飙升热词:可查看飙升词变化。通过对比关键词上期和同期的声量变化率计算声量飙升最大的词。
- 可点击飙升词与词云图、原帖展示联动,查看与此飙升词相关的原帖内容和高频词
4.品牌对标 #
从社媒热度、社媒口碑两个维度对本竞品进行对比分析,得出本品的优势、劣势、机会和面临的威胁
【品牌筛选器】
选择本品,每次只可选一个

【对标品牌筛选器】
选择进行对标的品牌,可选多个

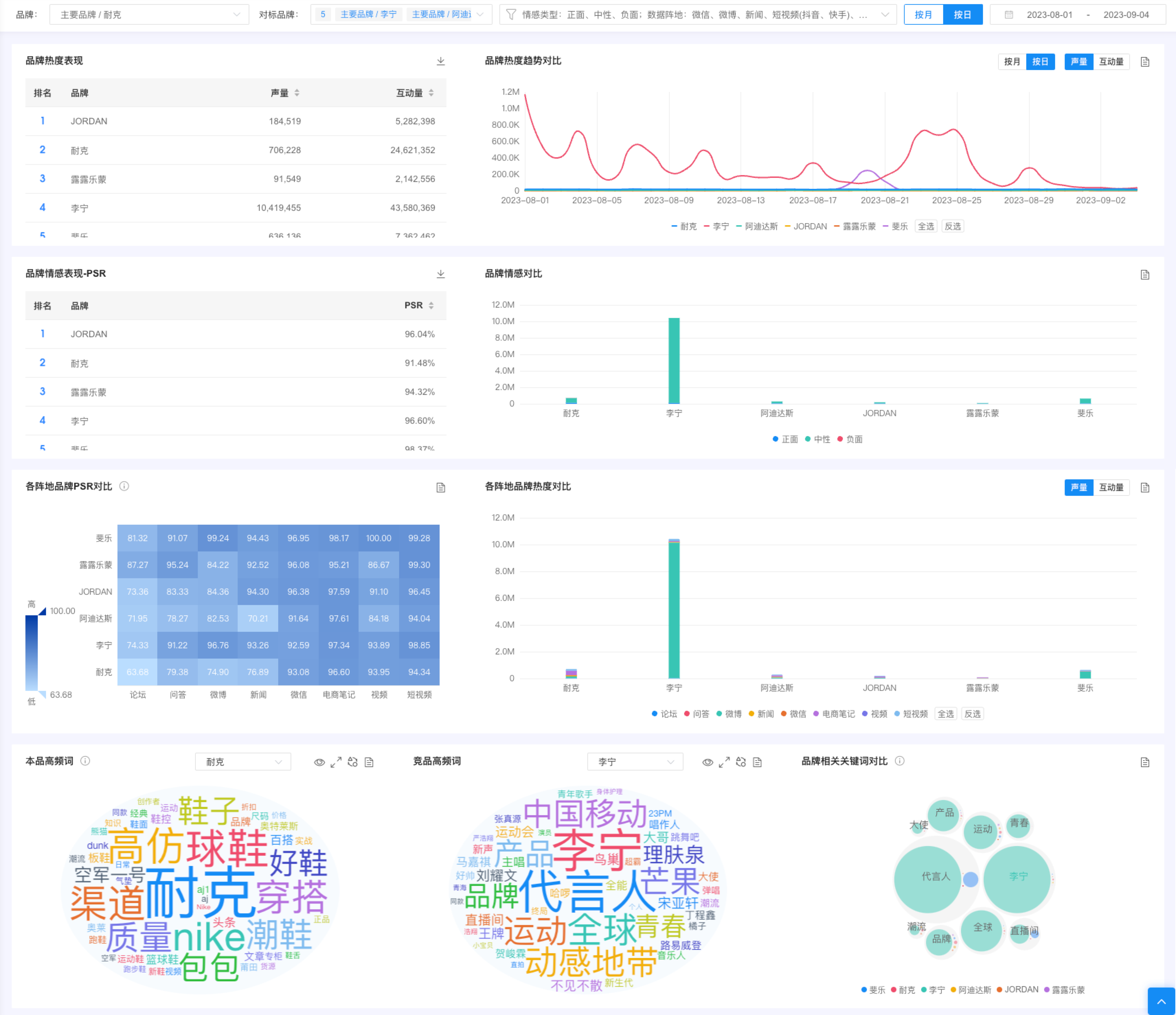
品牌热度表现:查看本品和竞品的声量、互动量指标,并支持按照热度指标排序
品牌热度趋势对比:可查看本竞品的热度趋势
品牌情感表现:查看本品和竞品社媒情感表现
品牌情感对比:查看本竞品的社媒情感表现
- 以图例区分不同品牌,可点击图例取消或选中某一品牌,仅影响品牌情感对比板块
各阵地品牌PSR对比:借助热力图,从阵地与品牌两个维度,迅速了解本竞品的PSR分布
本品高频词:在本品相关的帖子中,通过算法提取出的内容关键词,展示讨论度较高的词
竞品高频词:在选中竞品相关的帖子中,通过算法提取出的内容关键词,展示讨论度较高的词
- 可通过下拉选中竞品,查看某一品牌的高频词
品牌相关关键词对比:本竞品声量top 10的共同提及关键词,外圆大小无实质业务含义,内圆大小代表声量大小
5.微博/抖音人群画像 #
目前提供微博/抖音平台的人群画像,支持快速查看数据辐射人群画像信息,提高对受众的精准认知,辅助品牌方及时调整商业活动策略
此页面提供较全的画像维度,包括性别分布、年龄分布、认证分布、城市级别分布、地区分布、常用客户端、爱好标签、用户粉丝数量分布、活跃时间、关注用户排名、关注微博话题、话题原贴
图表标题均有注释说明,可将鼠标移入查看

附:核心算法说明 #
1.社媒营销广告算法:
品牌方在社媒投放广告后,需要对社媒营销效果进行归因分析,评估广告投放策略触达消费者的广度和深度。目前的社媒平台的内容可以大致分为品牌付费广告、用户自发内容、粉丝追星水贴、返利优惠广告、品牌新闻稿/公关文这几种类型。所以通过社媒营销广告算法将社媒数据分为内容营销广告、自发创作、追星文、促销团购、新闻公关。
2.关键词提取算法
从文本中提取出与这篇文档意义最相关的一些词,通过这些关键词就可以了解文本的主题思想。文本通过关键词提取后可以方便后续地摘要提取,文本分类/聚类等问题的处理分析工作
3.情感判断算法
用户通过发表内容表达自身情感时,主要包括正面、负面、中性三种倾向。数说基于自然语言处理及机器学习技术,深入挖掘用户不同情感的隐含特征,包括极致赞扬、粗鲁表达、特殊表情及符号折射的情感表达,并经过大量的情感标注数据,迭代优化情感判别模型。目前,数说情感判别模型准确率可达80%以上
4.文本指纹识别算法
文本指纹算法指的是对文本生成“数字指纹”,这个数字指纹是一个由字母和数字组成的32位的字符串,用这个字符串指纹来作为该文本的标识。文本指纹算法可以用来衡量不同文本之间的相似程度,指纹相同,文本也就越相似,此算法在文本去重,信息检索等文本处理任务有重要应用