当我们准备好了数据,接下来就可以对数据进行处理(过滤、合并、去重、打标签等),并对处理后的数据进行分析。
写在前面 #
在开始之前,我们先来捋一下处理数据和分析数据这两件事情的核心是在做什么。
分析数据:从数据中发现事实或问题,分析其原因,得出结论,辅助客户的决策。
其中,有几个重要部分:
数据:需要关注数据量、实时性、真实性、可读性。
分析:分析方法、维度、指标、统计结果。
结论:常见的有品类趋势、营销玩法、活动效果、品牌舆论等系统性的结论。
客户的决策:通常是产品营销、产品创新/研发等方面的决策。而处理数据的核心即提高数据的可读性或结构化程度,使我们能获得更多信息,直接的表现是数据有了更多字段,来更好地进行分析,得到更多、更深、更准确地结论。
给数据打标签 #
首先说明一下“打标签”的含义。
我们经常可以看到一篇微博帖子或小红书笔记中会带上一些tag,一是可以获得平台更多的流量,二是在个人主页,也可以根据tag来筛选帖子/笔记。打标签的作用类似于后者,我们可能会给数据打上品牌、人群、产品、粉丝层级等标签,在分析时就可以根据这些标签来筛选。
给数据打上标签,从数据表来看,其实就是多了一些列或者字段。
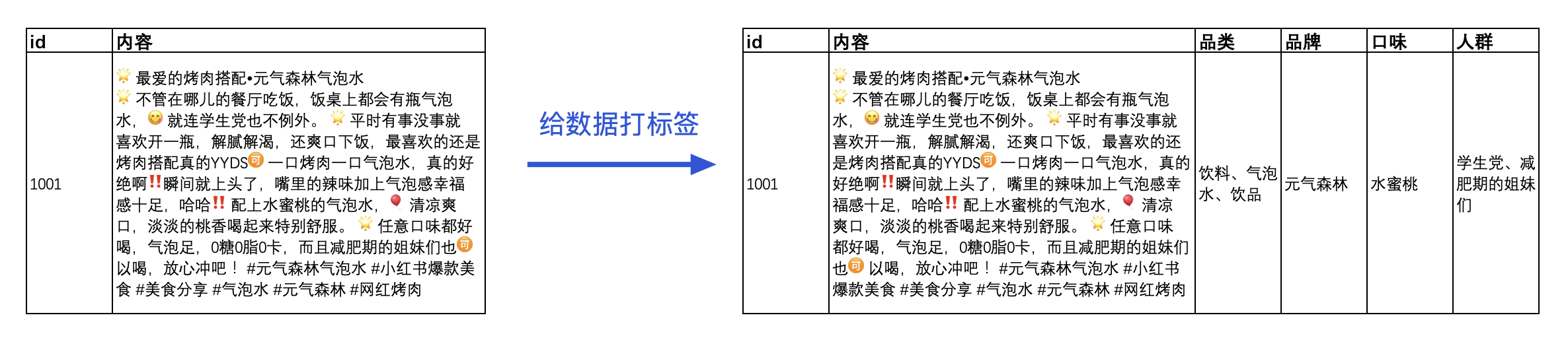
打标签的背后实际上是规则:什么情况下打上标签(最简单的是内容包含某些特定关键词)和打上什么标签值。例如上图中品牌标签的规则为:内容中包含“元气森林”时打上品牌标签,值为“元气森林”。
其次,打标签有两种方式,算法和码表。
算法可以简单地理解为已经定义好的规则,码表可以理解为自定义规则。由于不同客户的要求不同,所以码表这样的自定义规则是处理数据方式的强有力补充,应用广泛。另外,针对不同客户/行业,算法也可以进行专门的定制。
接下来,我们来看看如何在数说方舟上给数据打标签。
-
登陆数说方舟,在 「数据管理」 > 「数据地图」的桌面列表双击打开某个数据源,点击右上角「新建批处理作业」。接下来配置批处理作业即告诉系统我们要怎么处理数据。
-
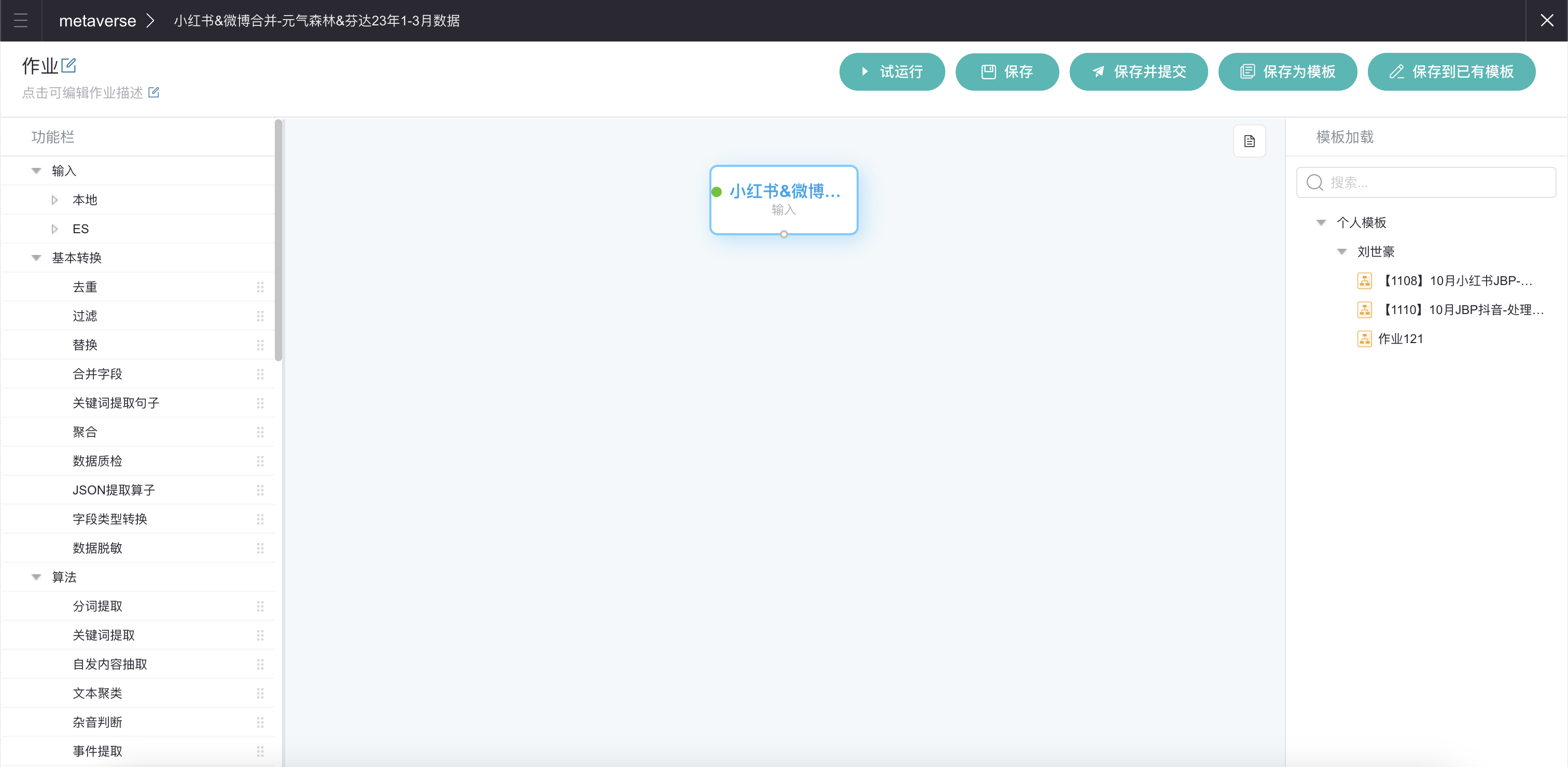
点击新建后我们将进入批处理作业的配置页面。
页面有几个主要区域:
左侧:数据处理步骤的列表,分为输入、基本转换、算法、标签、自定义、输出6类。列表的每一项可以称为一个算子。
中间:批处理作业/工作流。我们可以将左侧列表的算子拖拽至中间使用。
右上部分:批处理作业/工作流的操作按钮。
右侧:批处理作业/工作流的模版,满足周期性处理的复用需求。
一个作业/工作流包含的元素有输入、中间处理步骤(非必须)、输出。创建时已经读取输入的数据,接下来配置中间处理步骤和输出即可。 -
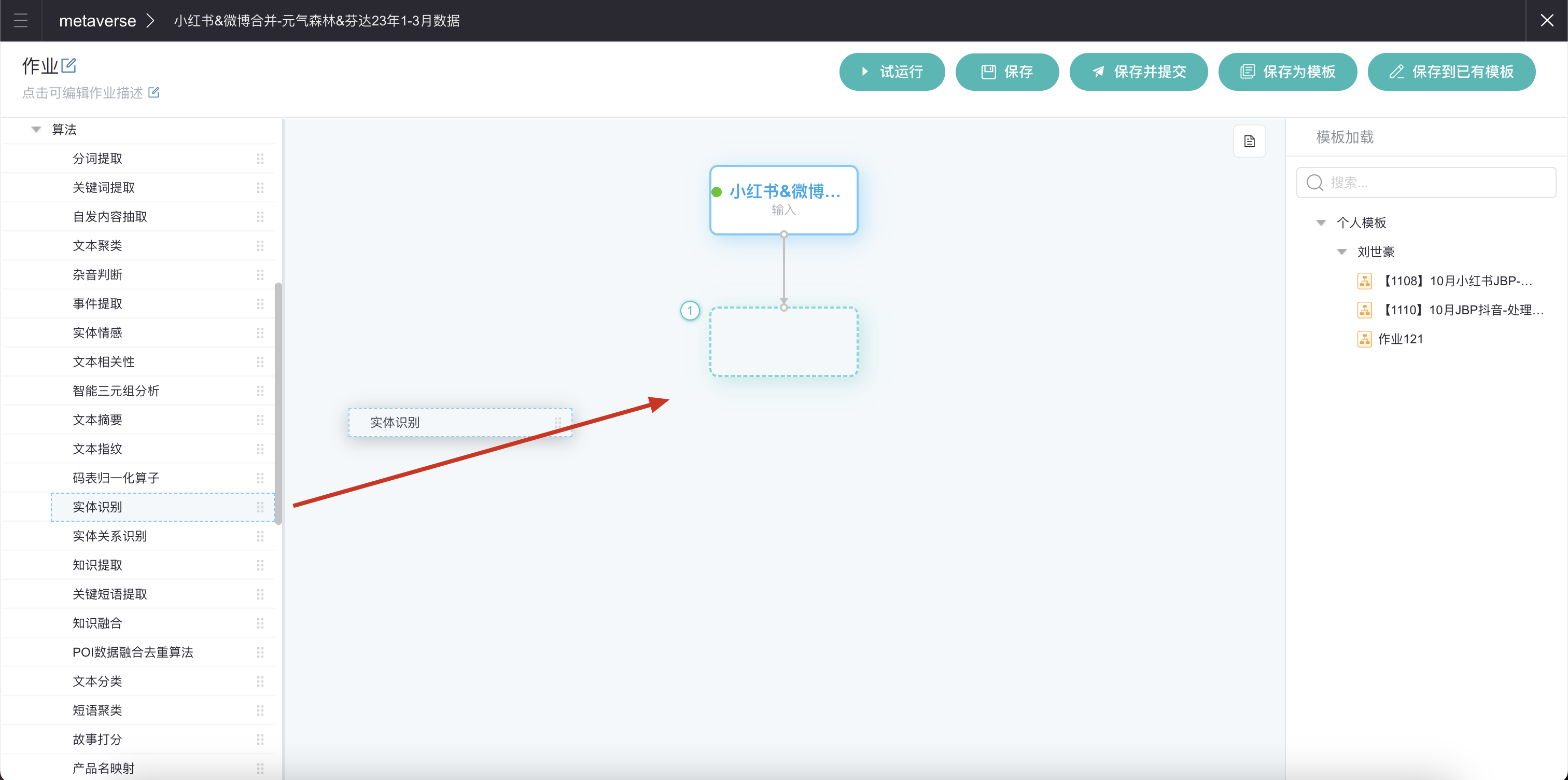
配置中间处理步骤。
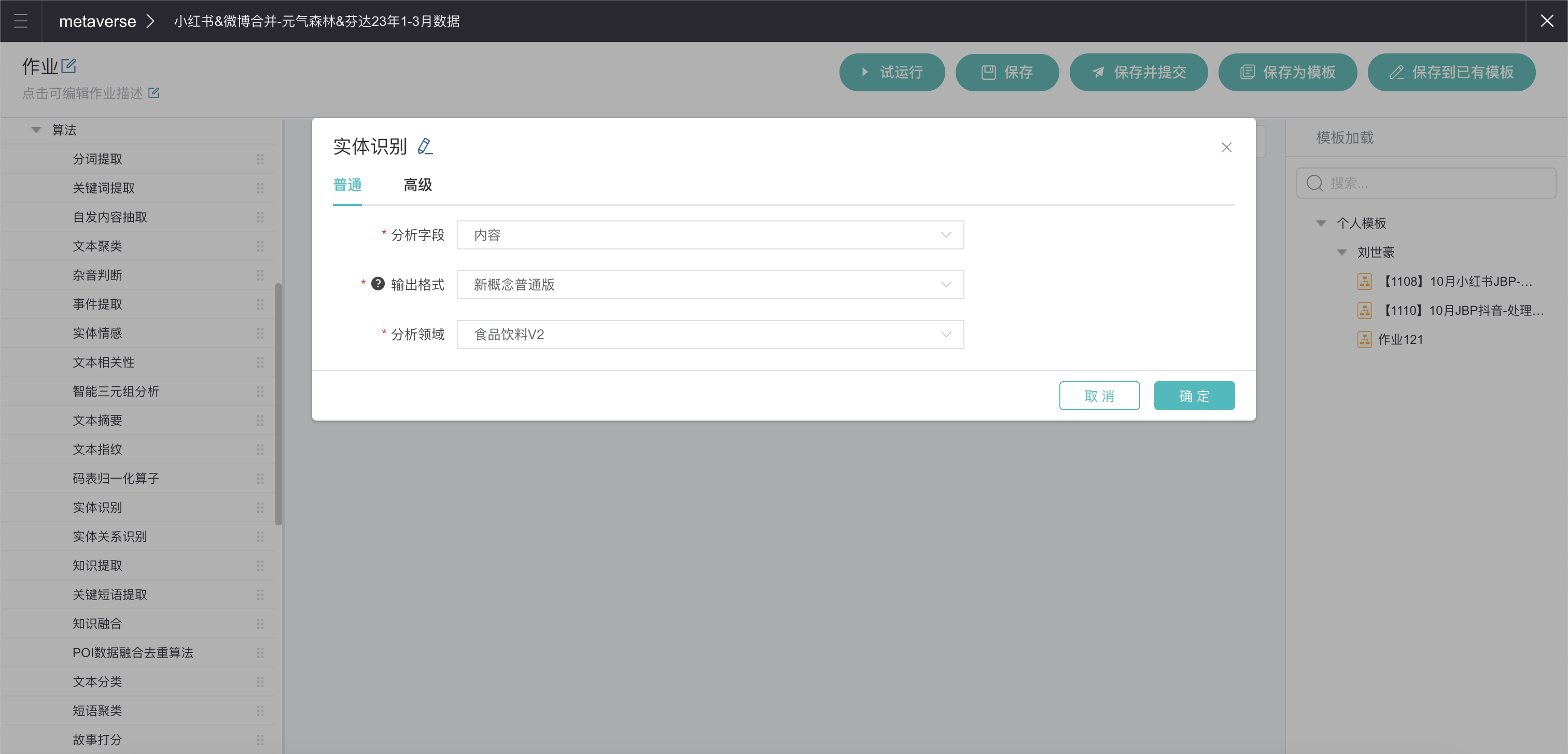
本次打标签我们使用「实体识别」算法。在左侧列表找到该算子后,拖拽至中间:
配置弹窗中的信息:「分析字段」代表识别哪一个字段中的实体,「输出格式」分为输出多列和输出一列,一列通常是研发使用;需要选择「分析领域」是因为实体识别这个算法针对不同行业领域进行了针对性的训练,根据实际情况选择即可,这里我们选择“食品饮料V2”。
除了直接使用的算子,方舟还提供自定义脚本、自定义算子等能力,用于定制化的处理步骤。 -
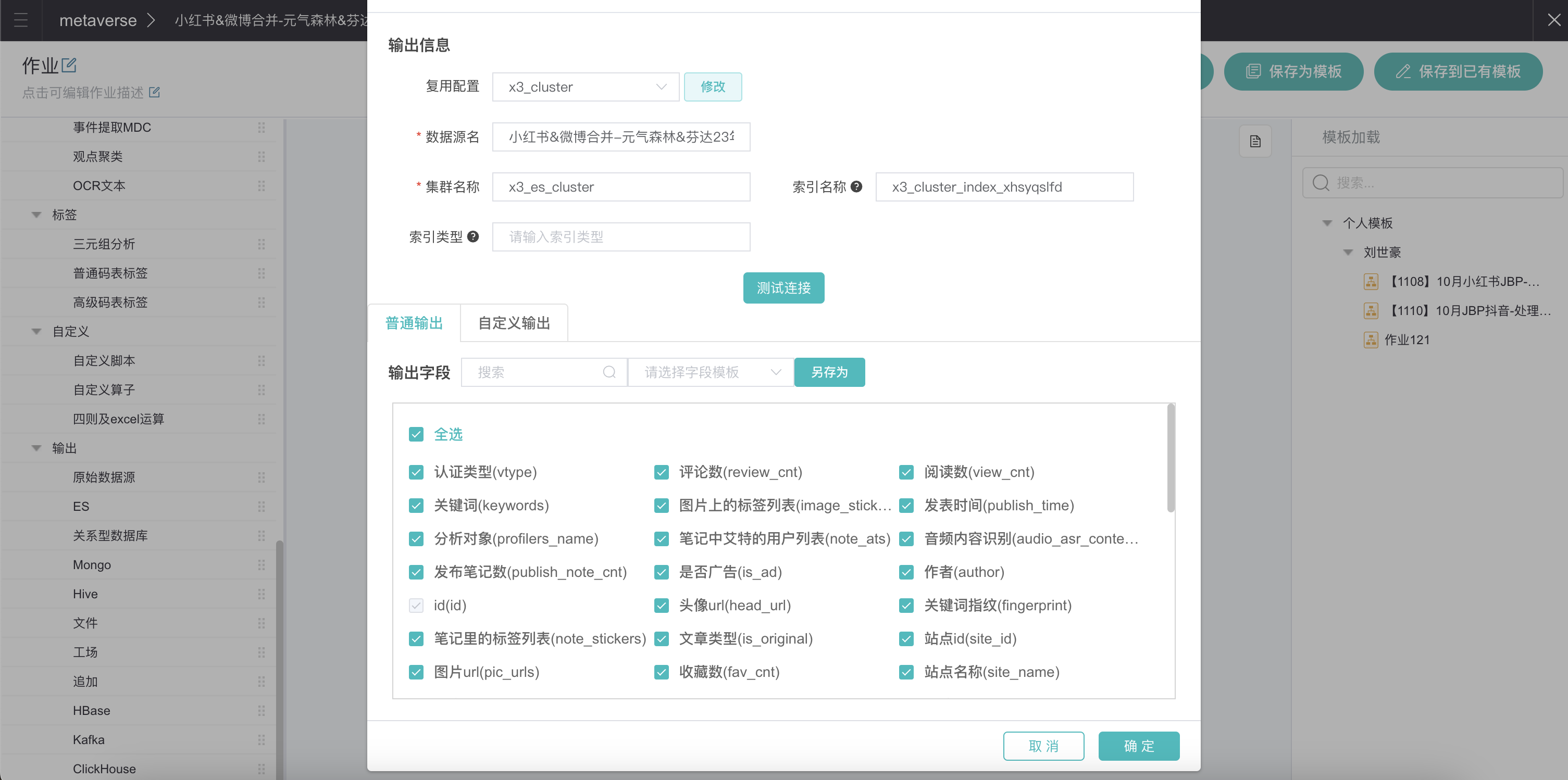
配置输出。
输出即处理完数据后,要将数据保存到哪里。常用的有ES、原始数据源、文件等。输出到ES会在「数据管理」中创建一份新的数据(ES指的是一种大数据集群),输出到原始数据源会在输入的数据表中直接追加/覆盖数据,输出文件会导出一份文件。这里我们选择ES,输出一份新的数据,名称为“实体识别-小红书&微博合并-元气森林&芬达23年1-3月数据”。
-
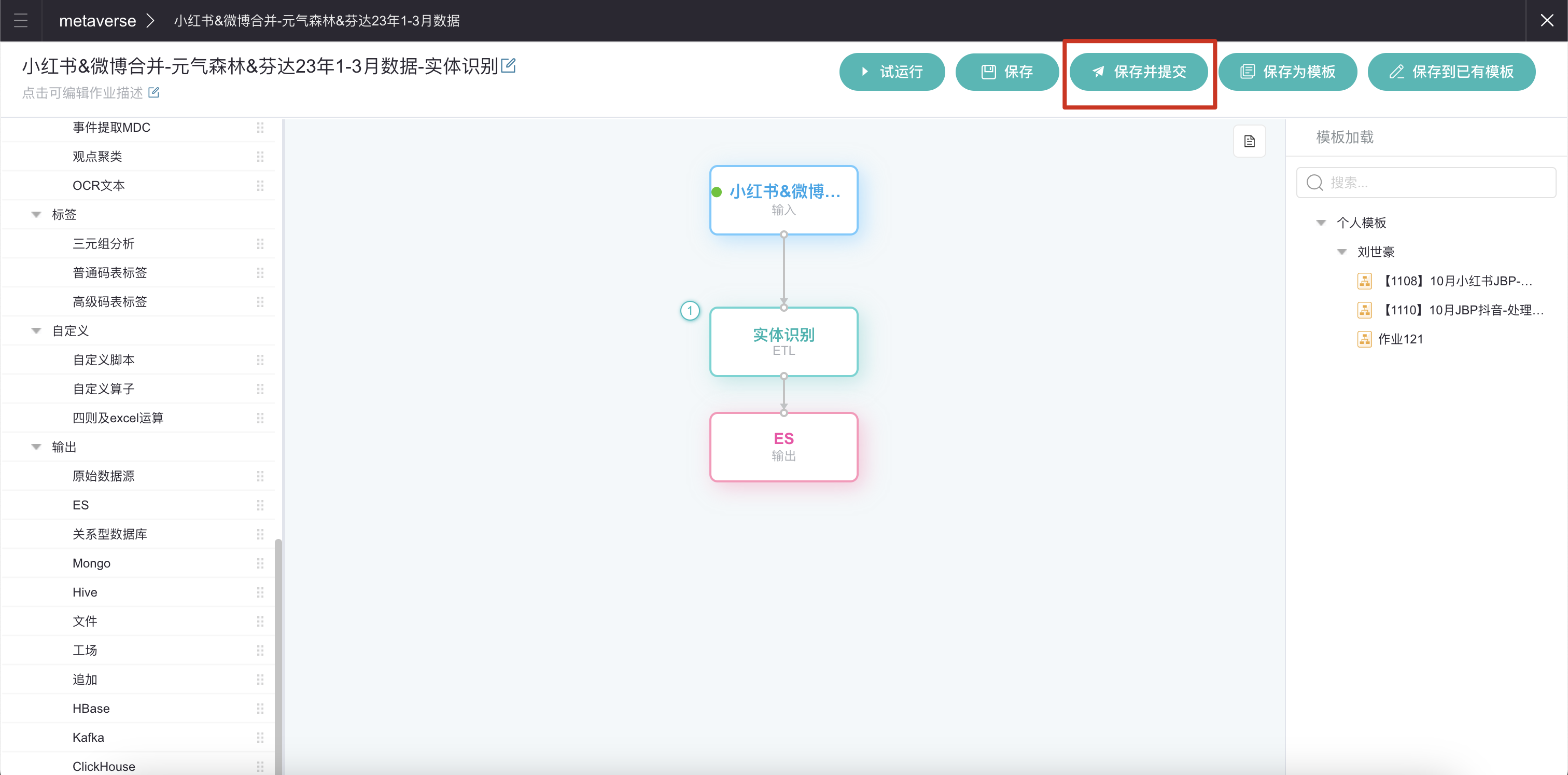
提交并观察作业/工作流运行进度。
点击右上角「保存并提交」,跳转至运行列表查看进度。
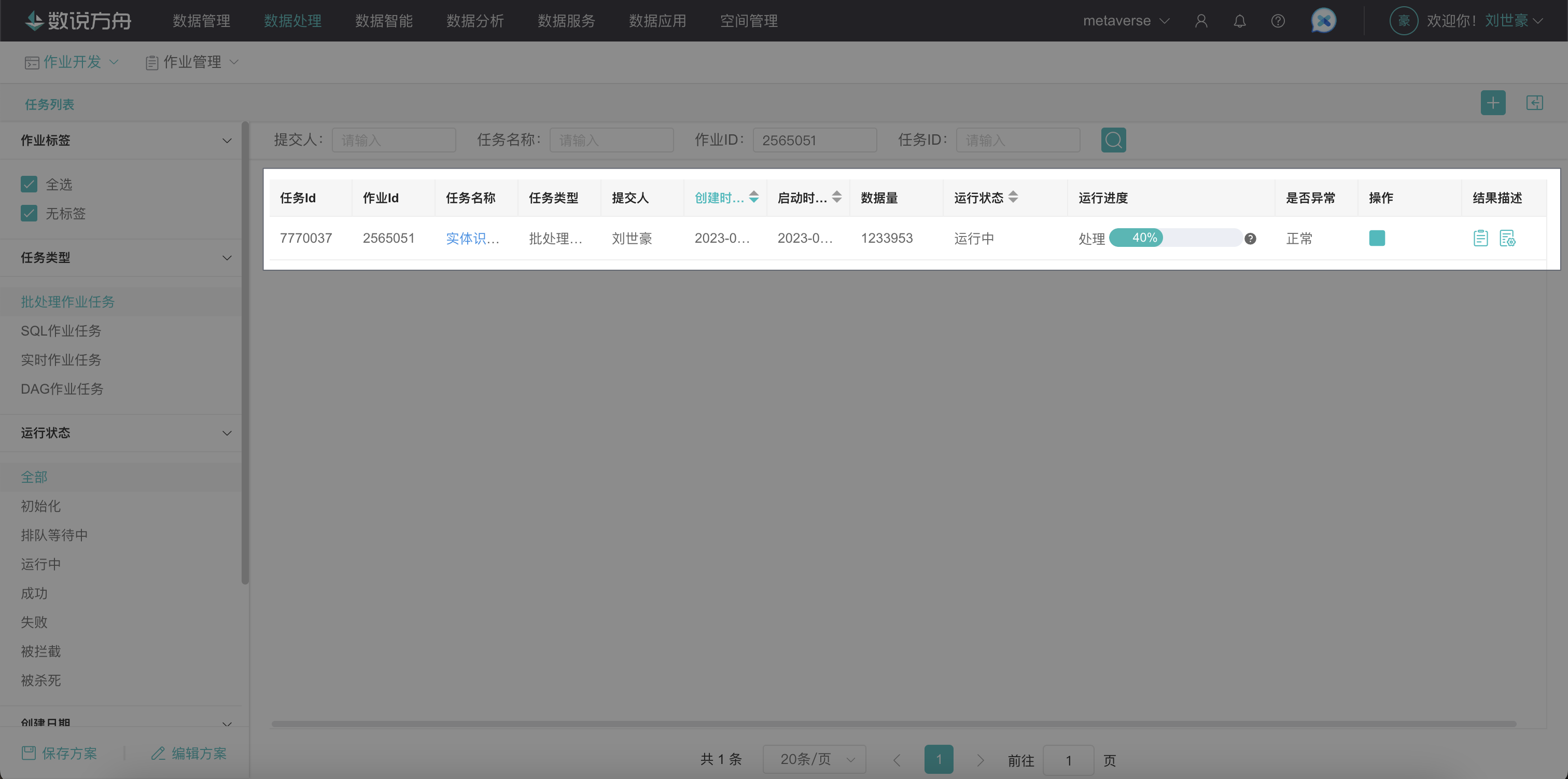
- 查看处理的结果。
作业/工作流运行完成后,我们回到「数据管理」找到“实体识别-小红书&微博合并-元气森林&芬达23年1-3月数据”这份数据,发现增加了品牌,品类,产品名,气味/味道,触感/口感/体验,成分/原料/材质,功效,科技/工艺,等14个实体识别算法输出的新字段。
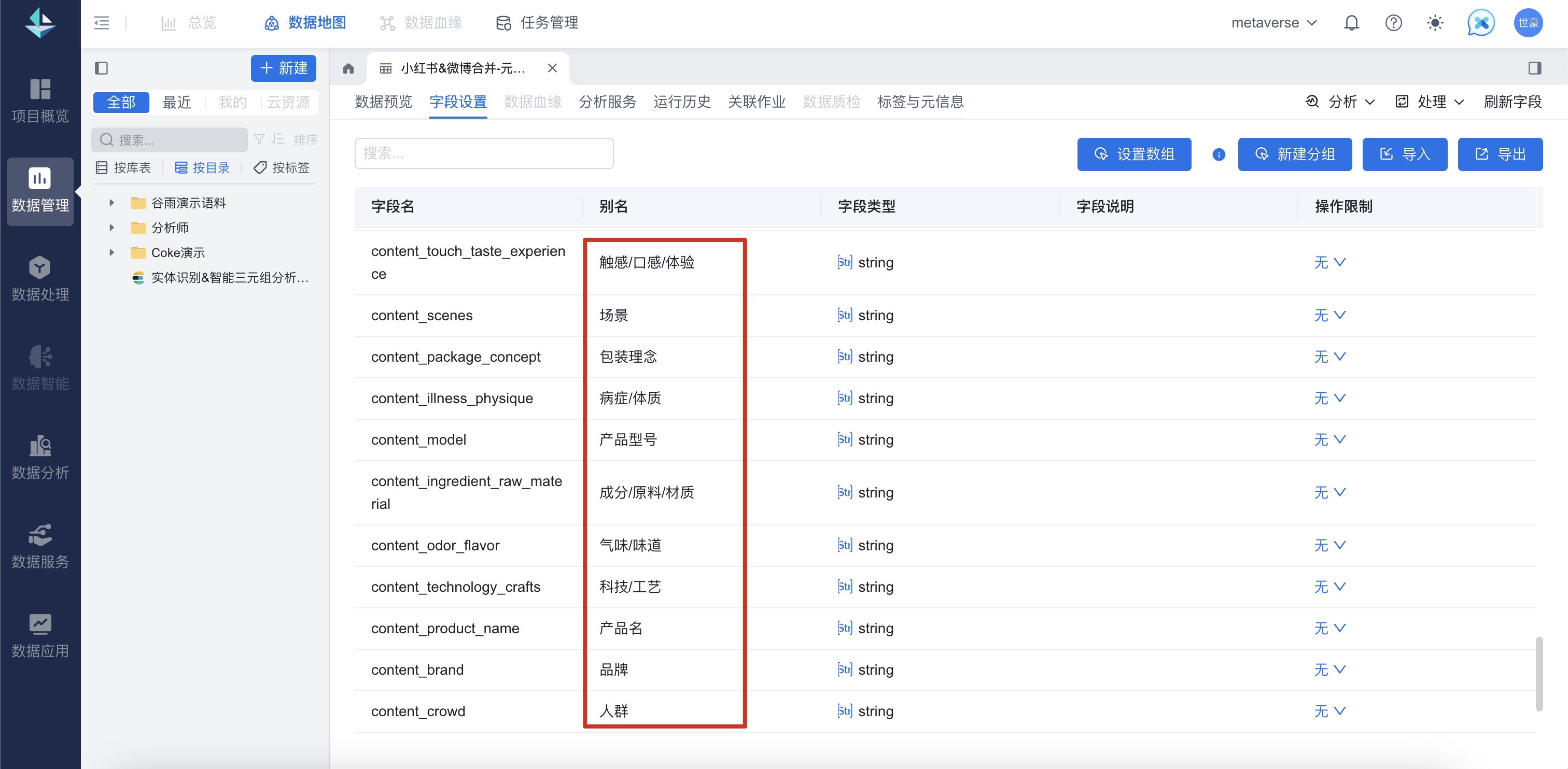
到这里,我们就完成了对数据的打标签,接下来就可以对数据进行探索和分析。
探索、分析数据 #
同样的,在「数据管理」模块找到上面完成实体识别处理的数据,点击右上角「新建数据分析表」。
创建后我们将进入分析表页面:
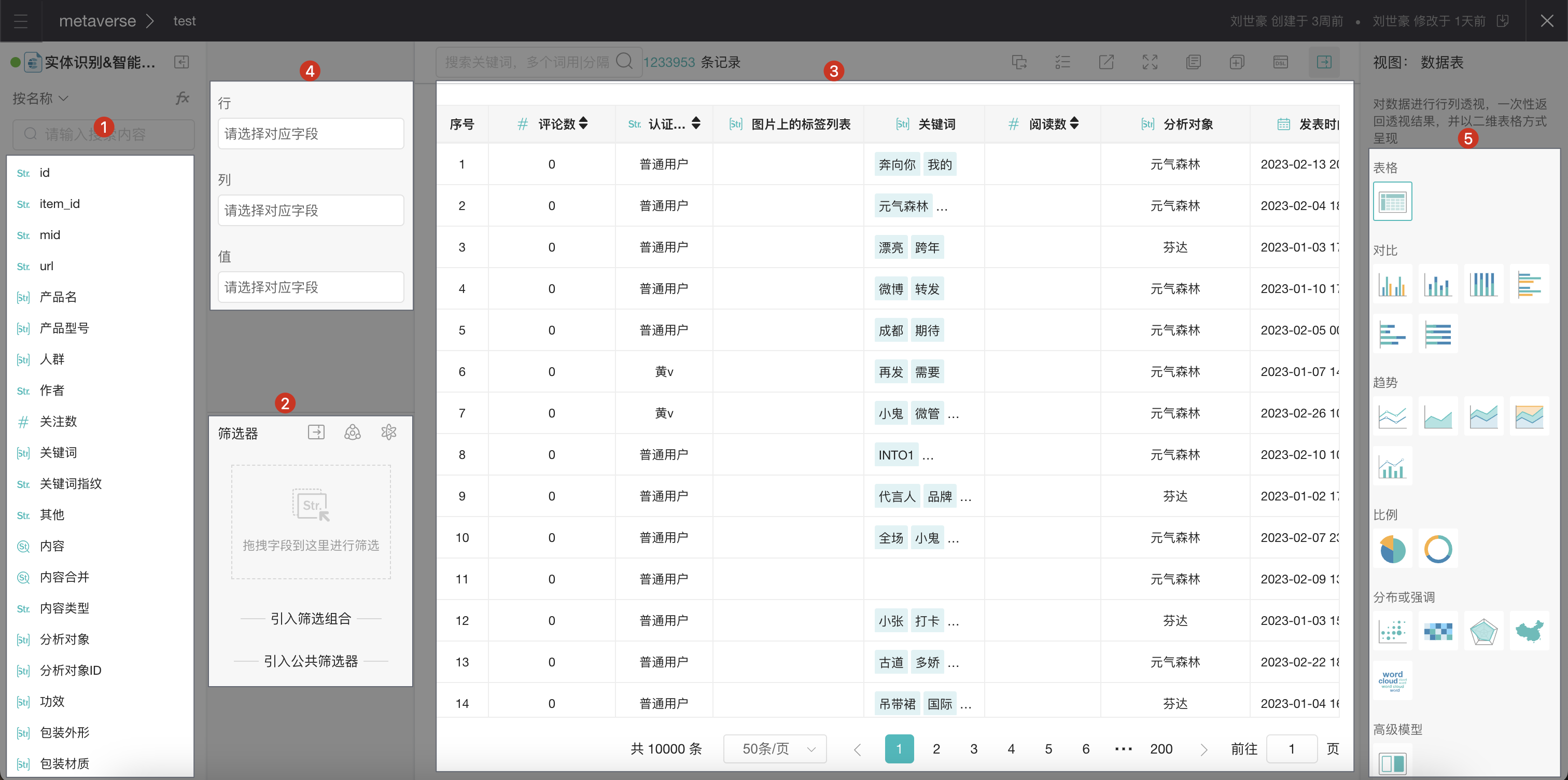
页面有以下主要的区域:
1.左侧:这份数据中包含的所有字段。
2.筛选器:用于配置针对数据的筛选条件,将左侧字段拖拽至此来配置。
3.筛选结果:在筛选器中配置条件后,将改变此区域的数据。
4.透视配置:跟Excel的透视表类似,「行」和「列」可以理解为分析的维度,「值」可以理解为指标。将左侧字段拖拽至此来配置,配置后在筛选结果的上方将出现透视结果。
5.分析图表工具:用于辅助分析的各类图表,包含柱状图、折线图、词云图等。
接下来,针对这份小红书和微博平台上,元气森林和芬达两个品牌在23年1-3月份的帖子/笔记数据,结合实体识别结果,我们来分析「UGC中讨论口味的声量变化和原文内容」。
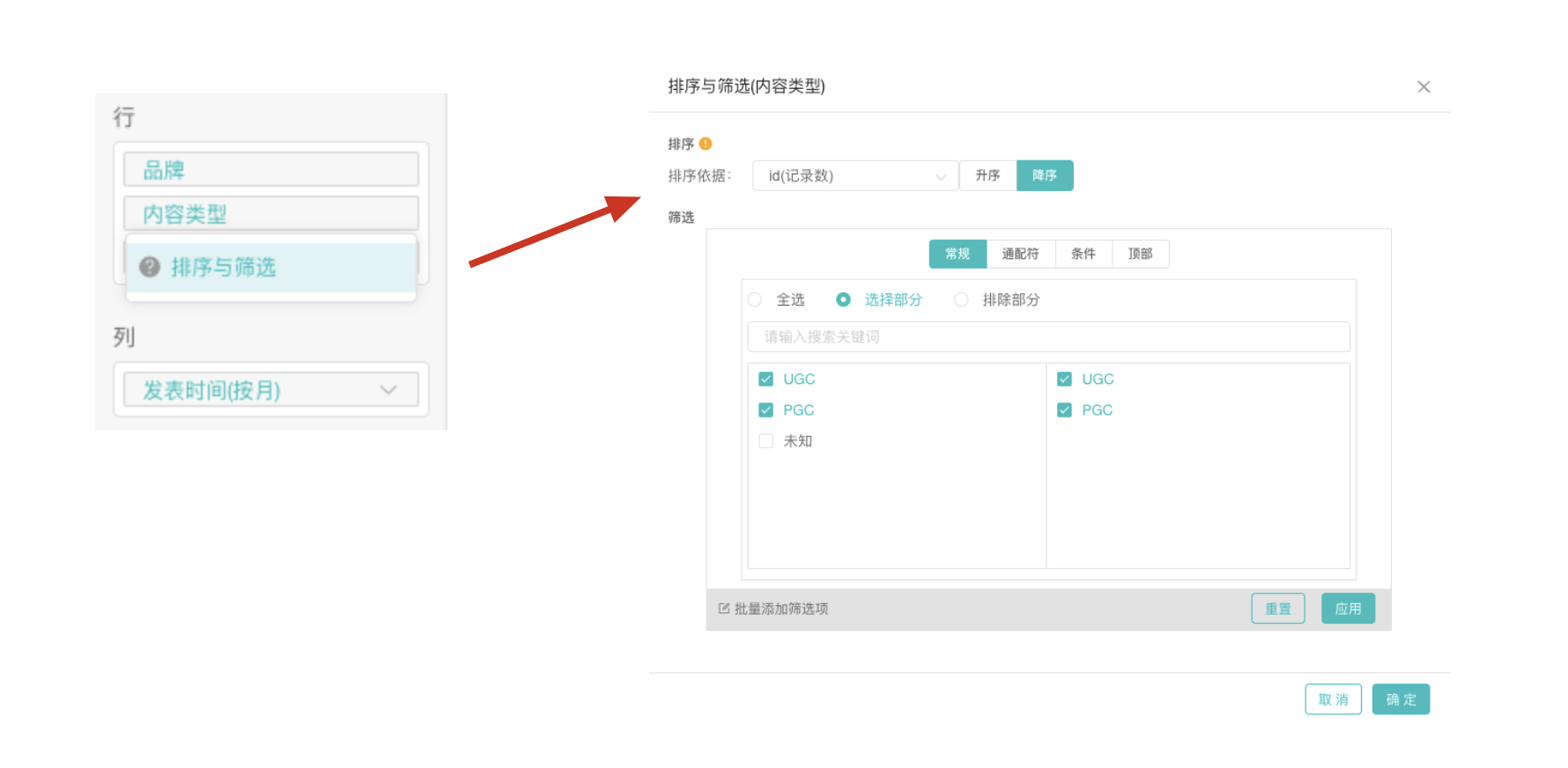
1.将“品牌”“内容类型”“气味/味道”字段拖拽至「行」,将“发表时间”拖拽至列,将“id”拖拽至「值」。点击“气味/味道”字段,设置排序;点击“发表时间”字段,设置按月。此时我们就可以知道小红书和微博平台上,元气森林和芬达两个品牌在23年1-3月份的帖子/笔记中的声量变化,以及其中都讨论到了哪些口味。
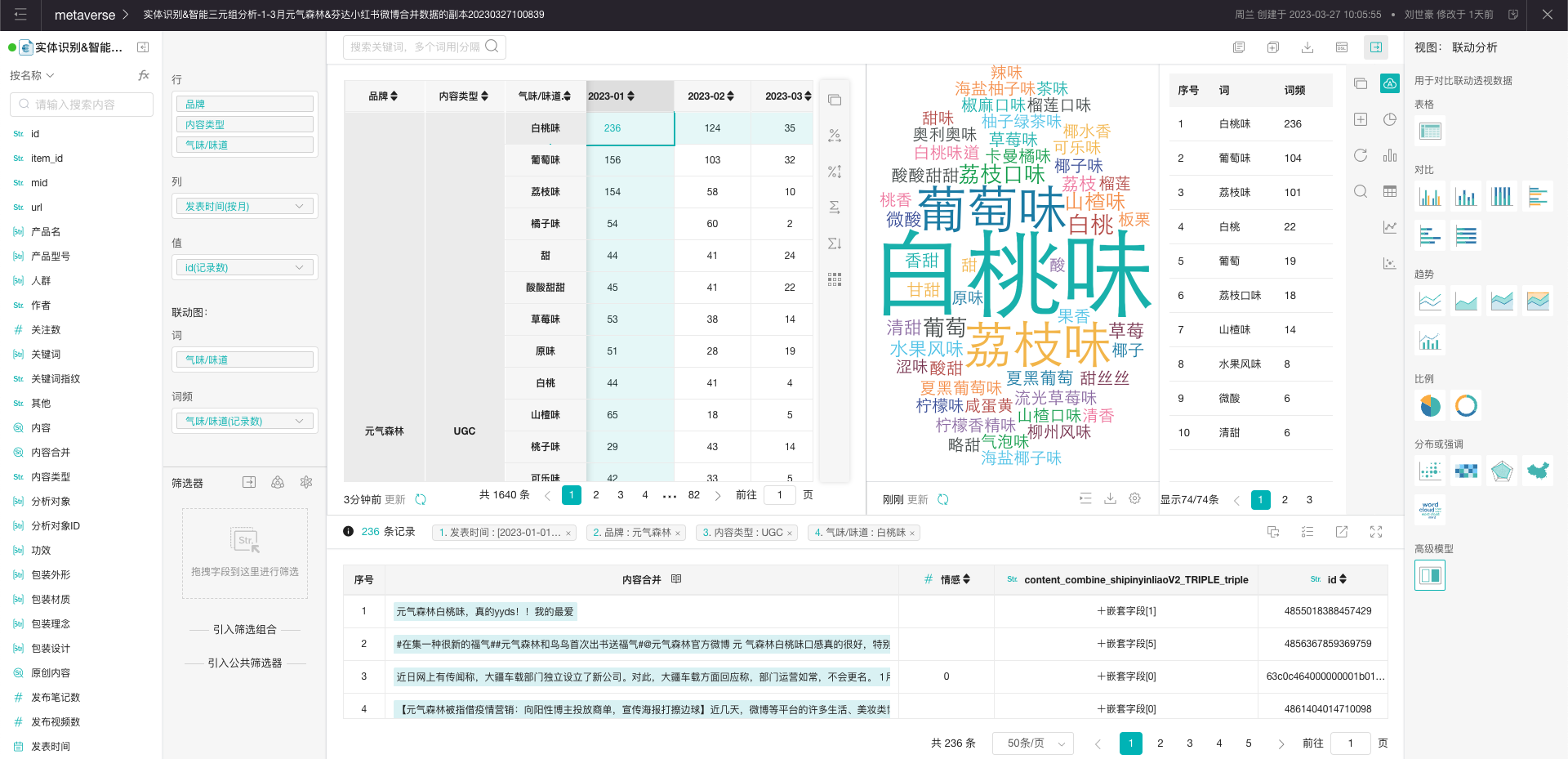
2.在页面右侧区域点击「高级模型」,透视结果右侧将会出现一个新的区域,将“气味/味道”字段拖拽至「行」「列」「值」下方的「词」中。
3.点击透视结果的某个单元格,例如元气森林 > UGC > 白桃味 > 2023-01,此时透视结果右侧的词云图、下方的筛选结果相应地出现了变化,也就是词云图、筛选结果都应用了透视表中的筛选结果,我们称这种效果为联动。此时我们就可以知道1月份小红书和微博平台上,元气森林的帖子/笔记中对白桃味的讨论会同时提及哪些味道(词云图),以及这些讨论的原贴/原笔记是什么(筛选结果)。
结语 #
至此,我们就在数说方舟上完成了对数据打标签、分析打标签后的数据,你可以在作业/工作流中使用其他算子、在分析表中自行组合更多的字段和图表来探索、分析数据。
开启你的数据之旅吧!💫